
Workflow Observability: Finding and Resolving Failures Fast
Picture yourself trying to manage a CI/CD workflow across different clouds without a clear view of each step and interaction. It's like navigating a complex, ever-changing maze with a blindfold on. This is even more challenging in complex workflows with multiple related processes. This complexity creates a network effect across tasks, making them close to impossible to debug.
To manage this complexity, observability isn’t just a requirement - it’s a necessity. In this article, we’ll explore best practices for observability to ensure your workflows are operational and easily managed at scale.
Why we need workflow observability
Observability is the backbone of identifying and resolving failures. It ensures that teams can meet their service level agreements (SLAs) and facilitates seamless communication between teams. You may believe that workflow errors originate primarily from data - but data is moved and stored. In reality, these errors can come from anywhere: infrastructure, models, API connections, external tools, etc.
You might be thinking of data quality tools right about now - and you’re right in that they are broadly used. Consider dbt tests, which can catch data-related issues. But what about the architectures that surround data, as in how it’s moved and where it’s stored? If you focus solely on data, you’ll miss other critical errors - such as unreachable 3rd party APIs, missing files in object storage, or a virtual machine instance that’s spinning its wheels.
Furthermore, observability at the data level is an observation of symptoms without the ability to influence the root cause or treat the symptoms. When observability lives at the workflow level, reacting to failed workflows with a stop-gap is feasible. For instance, consider a failure to be an event that triggers a backup process to run to continue to meet SLAs.
With comprehensive observability, teams can not only quickly identify where a failure has occurred, but also what other processes have been affected by the failure and quickly react to the situation automatically. Observability dashboards enable you to debug and resolve issues swiftly, maintaining the integrity and reliability of all your workflows and ensuring your team hits their SLAs.
At its core, observability fosters better communication and trust between teams. Quick communication in a complex environment means more efficient problem-solving, a tighter feedback loop, and fundamentally: trust.
Do you have the correct picture of reality?
This section was largely inspired by a talk at Coalesce 2023 by our Director of Growth Marketing, Sarah Krasnik Bedell. You can find the recording here.
Consider the scenario of reconciling refunds in an e-commerce company. Imagine your workflow is set up to run with Slack notifications for any failures. One day, the flow fails. It triggers a Slack message that, unfortunately, goes unnoticed because it's in a channel that is overrun with other irrelevant alerts.
Later, you realize that the reports are outdated. You log into your data source, only to be greeted by errors that send you on a troubleshooting expedition. You first suspect an issue in accounting data. So you dive into various logs – dbt Cloud, your data warehouse, even your machine learning models. But where, exactly, should you look? It's hard to determine if what you're looking at is directly related to the problem. Hours pass as you struggle to make sense of the situation, failing to find a breakthrough.
Then, a conversation with a colleague sheds light on a crucial aspect you overlooked – the brittleness of the Quickbooks API and its frequent need for key rotation. It turns out the issue is with a Fivetran job that uses the API, as refund reconciliation depends on POs and entries found in Quickbooks. Why couldn’t you discover this earlier? Simple answer: your logging was obscure and not up to the task.
Debugging doesn’t scale when all your dependencies aren't centrally trackable. In a complex workflow environment, dependencies can span various tools and platforms. This makes it harder to perform root cause analysis. Each troubleshooting session becomes time-consuming and often fruitless without a centralized system to track these dependencies and their interactions.
These troubleshooting sessions aren’t just painful for you, the engineer. They cost the company your time and potentially lost money - either because it took you away from product work or because you lost revenue due to downtime.
Attaining full workflow observability
You can achieve better workflow visibility by following three cardinal principles:
- Treat workflows as applications
- Encode your dependencies
- Loop people in
Let’s look at each one in more detail.
Treat workflows as applications
Workflows aren’t just data conduits. They’re applications.
What do I mean? Consider the similarities:
- Workflows have features and users just like applications. Think about the features of applications. They have an API layer, users, and stakeholders that depend on their functioning and existence. Workflows have their own users, dependencies, architecture, API, and interactions. Critical workflows are just as important in their criticality as applications, both for internal and customer use cases.
- Workflows, like applications, are multifaceted. This demands a holistic approach to management, ensuring that each component is well-understood and meticulously monitored. It’s important to have a clear map of how the workflow interacts with various elements of the broader infrastructure and engineering ecosystem, such as data sources, processing tools, API dependencies, and output channels. This understanding helps in identifying upstream issues that could potentially disrupt the workflow. For instance, a change in an API's behavior or a modification in a third-party system can have cascading effects on the workflow. You can address this preemptively if these dependencies are well-understood and monitored.
- Workflows have a lifecycle. From development and deployment to maintenance and eventual retirement, each stage of this lifecycle has unique challenges and requires specific management strategies. For example, during the development phase, you’ll design the workflow for scalability and maintainability. During deployment, you need monitoring to identify and fix any initial issues. During maintenance, you’ll leverage monitoring for ongoing monitoring, performance optimization, and updates.
💡Quick tips: Test workflows with the same level of scrutiny as you would applications; additionally, incorporate manual intervention precisely when it's needed, not on a schedule, in your workflows.
Workflows can be just as interactive and just as critical as applications. By treating workflows with the same rigor as you would when building applications, you can ensure that they’re as robust, reliable, and scalable as any other critical engineering system.
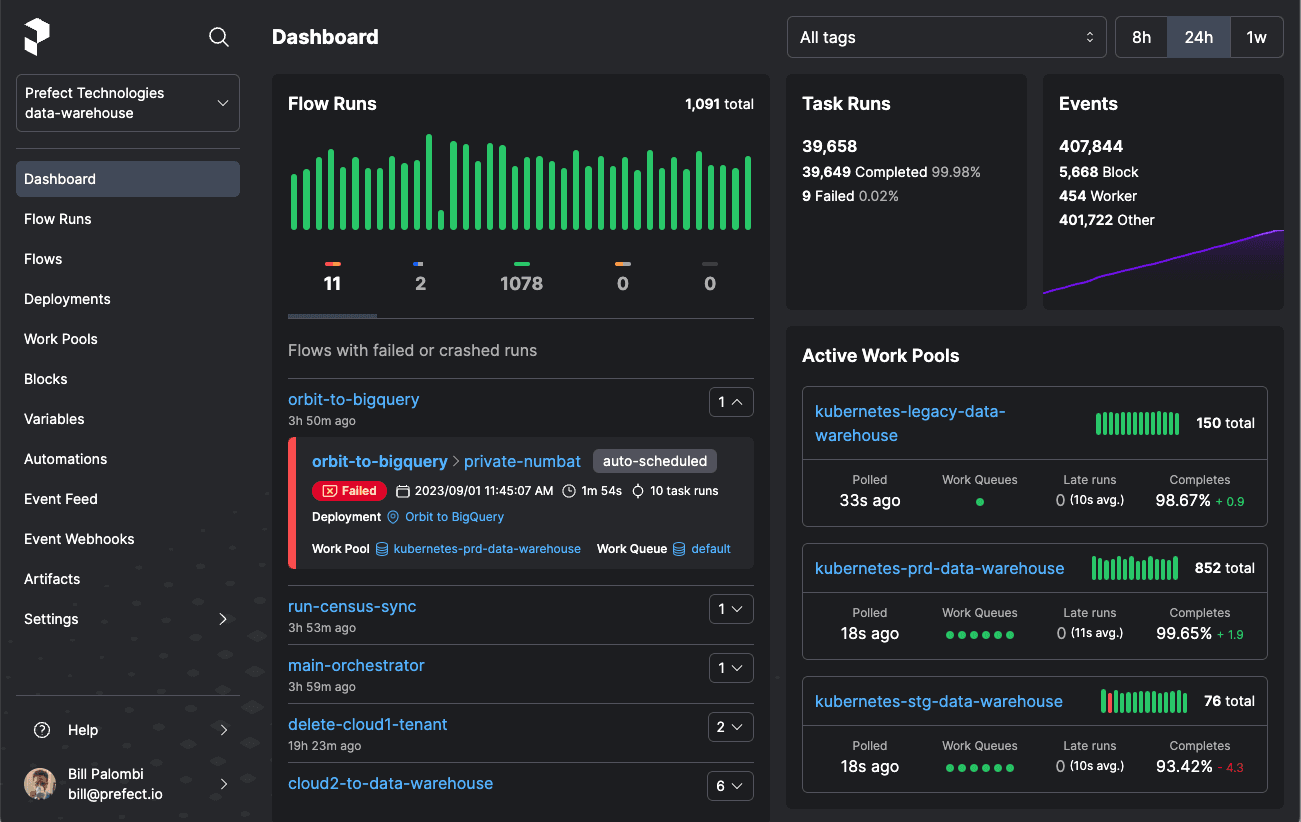
Encode your dependencies with centralized orchestration
Dependencies across applications are encoded as API specs. Why shouldn’t workflow dependencies be encoded if they are equally as critical?
The key to efficient and reliable operation of workflows lies in the concept of centralized orchestration. This ensures that workflows are completed successfully and are well-coordinated, taking into account all upstream and downstream dependencies.
Encoding dependencies is about making explicit the relationships and interactions between different components of the workflow. This requires documenting and versioning them in a way that doesn’t rely solely on human knowledge or memory.
Centralized orchestration means drawing clear lines through the different pieces of the workflow and connecting them. This connection can be through data pipelines, API integrations, or other means of communication that allow different parts of the workflow to inform and influence each other. At its core, though, the centralization happens through versioned code that can be tracked over time.
You can think of treating workflows as data points. Every aspect of a workflow's execution – from start to finish, including all interactions and dependencies – is a valuable piece of data that can be monitored and analyzed. This data provides insights into the workflow's performance and helps identify areas for improvement.
💡Quick tip: A centralized dashboard provides visibility into these data points.
When you visit your dashboard, it’s usually because you suspect something went wrong! Having all this data in a single place, no matter where it lives in your infrastructure, enables your team to analyze root causes and fix issues quickly.
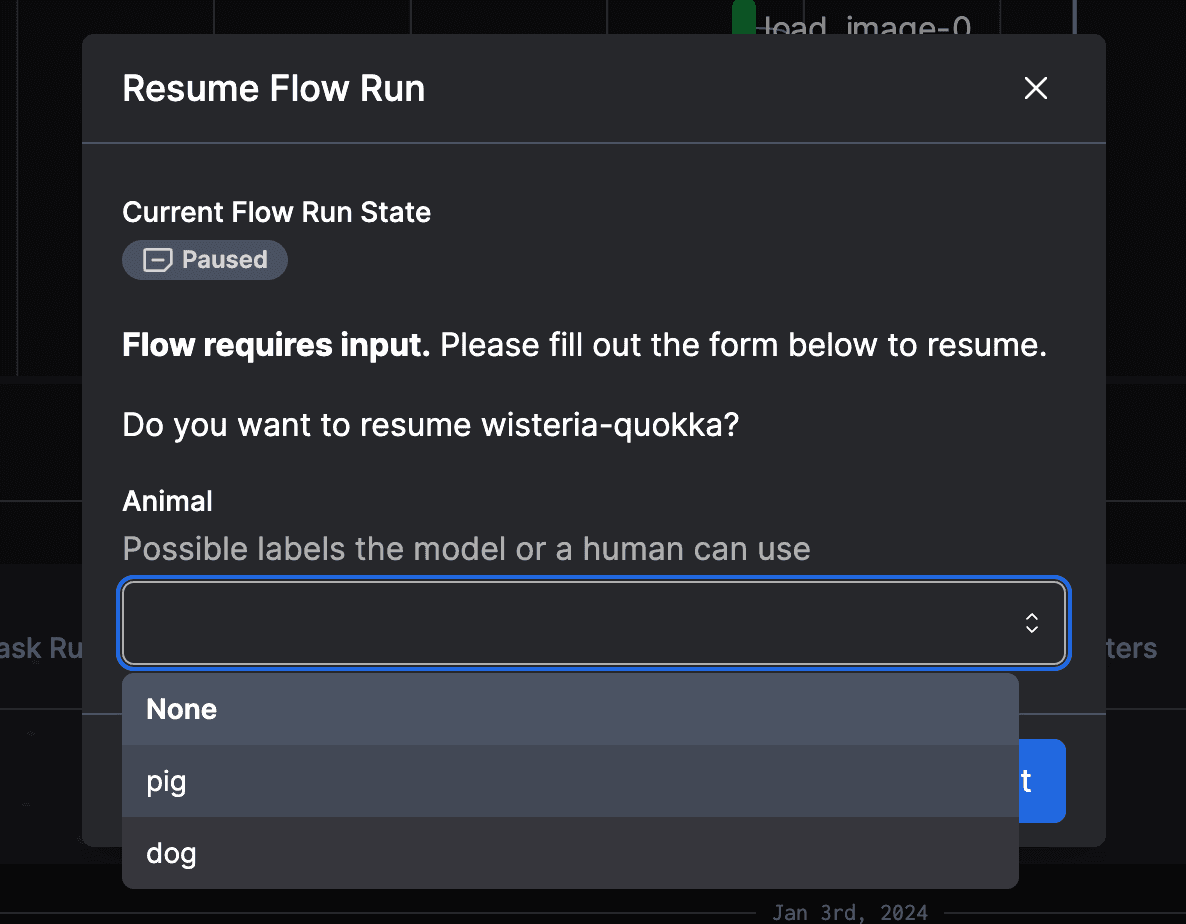
Loop people in
The more complex your workflows are, the more important it is to keep all your stakeholders in the loop. Recall the example about the refund workflow above. Once you knew about the Quickbooks API interface, the pieces of the puzzle fell into place. Complex workflows are like this. Since they tie multiple systems together, they usually require multiple people with expertise in each area to analyze and unearth a root cause.
Looping people in goes beyond sending automated notifications or Slack messages about issues. While such alerts are useful for immediate awareness, they often lack the necessary context to be meaningful. For instance, a message stating "X field was null" signals a problem - but it doesn't provide insights into why the issue occurred or how it impacts the broader workflow.
In addition, the relevant level of context needs to be communicated to the appropriate audience. A null error might mean something to a data team member. But it may mean nothing to someone on the accounting team trying to reconcile refunds.
It's essential to have a system that not only alerts teams to issues but also provides them with access to detailed logs, data visualizations, and analysis. This system should enable team members to dive into the specifics of an issue easily, understand its place in the larger workflow, and collaborate on finding a solution.
💡Quick tip: Give end users access to logs that are summarized and aggregated with context.

Get the correct picture of reality with Prefect
Gaining a clear and accurate understanding of your workflows is crucial for efficient data management and processing. Prefect offers a comprehensive solution to achieve this through its advanced workflow orchestration system, coupled with an observability layer across workflows and infrastructure. With Prefect, you can manage and monitor your workflows no matter where their components live in your infrastructure.
Try Prefect today and start transforming how you manage your workflows.
Related Content








