
Why You Need an Observability Platform
Oftentimes, writing a useful bit of code is the easy part. The hard part, the punishment you receive for doing something useful, is the nebulous job of productionizing it. If you’re lucky, your organization has a single, clear path forward - how to containerize, deploy, schedule, and monitor your workflow in a production environment. Many of us are not lucky. Prefect paves the golden path to a production-grade state.
To easily maintain production workflows you need an observability platform, which enables scripts to be true applications that can be observed, interacted with, and relied upon - common tenants of well-engineered software.
Production is Painful Without Observability
Let’s back up. Earlier in my career, I made a living writing internal tooling scripts for a customer success organization. My scripts were dope; my knowledge of software engineering best practices was not. Putting a script into production was a simple nine step process:
- SCP a file up to an EC2 server
- SSH into the EC2 server
- Screen into a long running terminal session I kept open for background jobs
- Edit a crontab to run the script on a schedule, usually scheduling each new script to start about an hour after the last one to avoid hitting resource limits
- Do a little kung-du to see if i was running out of disk
- rm some log.txt files laying around
- Restart my cron service with /etc/init.d/cron reload
- Detach the screen, break the ssh pipe, and finally
- Not quite pray, but hope to something larger than myself that nothing would go wrong
If things never went wrong, this process would have probably worked well. And it did, at the beginning. As the number of jobs I maintained grew, reliability went down. Scripts and servers crashed, downstream data was stale, and automations failed silently. And so, slowly but surely, I added a number of well-intentioned but misguided hacks.
Retries on error prone tasks
Sometimes the causes of failure were random or transient. To combat this, I wanted scripts or functions to retry with the same logic in the off chance that time itself would resolve the issue.
Retrying tasks is part of observability, whether a platform or framework, intended to reduce random errors automatically.
So, into the script itself, I added code like:
1attempts = 0
2max_attempts = 3
3for i in range l:
4 try:
5 thing()
6 except Exception as e:
7 print(e)
8 if attempts < max_attempts:
9 try:
10 thing()Notifications on script failure
When a script inevitably failed, I wanted to know about it immediately, not when I just happened to remember to check things out by SSHing into the server.
Failure are inevitable, which is the whole reason observability is important. You need notifications to know when critical failures occur.
Commonly using Slack, I added code to send a message:
1#final attempt
2try:
3 thing()
4except Exception as e:
5 notify_slack(webhook=os.environ("SLACK_WEBHOOK"),mssg=e)Concurrency Controls
I needed to ensure that I didn’t cause the server to crash due to running out of memory, so I wanted to enforce that only one script could run at a time.
I have blacked out the implementation details here to protect my psyche, but I essentially had a separate semaphor process running that only allowed a certain number of python PIDs to execute at once. This, combined with my liberal use of os.subprocess.Popen() from within actual running scripts, made things strictly worse, not better.
There's one type of failure this tackles - failure due to infrastructure overload. Spoiler alert - an observability platform would encompass all types of failures, not just code failures within a workflow, and send notification reliably even when the problem was with infrastructure.
And so life went - every morning, I would SSH into my box and hope for the best. Some days, things were awesome and I could see based on lower level process IDs that things were adhering to my expectations. Sometimes, my SSH connection was refused. Not an auth error, a straight up failure to connect error, which means the server died overnight. There was no mystery who killed it. It was me.
The Path to an Observability Platform
While hacky, I was attempting to implement some of the key tenants of an observability platform. And I got the components right, however hacky.
An observability platform enables you to understand and react to workflows in a scalable way. With end-to-end observability, you can understand all of the variables and dependencies that threaten a workflow’s successful execution. Reacting automatically through retries and concurrency leads to less manual intervention.
The key components of an observability platform are:
- Automated task retries to prevent random errors taking up debugging time
- Notifications on failure to ensure fixing can begin quickly
- Concurrency controls to protect from avoidable infrastructure failures
My approach fell short because it was not scalable or reliable - I had no way of seeing what was happening in the myriad failure modes I was falling into.
Production as Paradise With Observability
A basic tenant of production quality software is its ability to be observed - or to answer - given an expectation about a process that did run, is running, or should run - how does reality differ from my expectation? For this reason, an observability platform is a key tenant of production software. Without observability in a centralized place, it is impossible to reliably answer these questions.
I didn’t know it then, but an ecosystem of workflow orchestrators was beginning to take shape in the market with this problem firmly in its crosshairs. Now, I work for one of them.
Prefect allows you to transform your scripts into workflow applications with only minimally invasive code changes. As such, Prefect is powerful - it can run scripts on serverless infrastructure, parallelize your processes, surface AI-powered insights, and more. Traditional workflow orchestrators fall short because they stop here - Prefect on the other hand offers observability in a centralized platform with useful visualizations that exist for the core purpose of helping developers debug failure.
But production means different things to different teams, and sometimes, it means you just need a dead simple dashboard to see with your own eyes what the heck is going on with your Python. At Prefect, we believe in incremental adoption, or, only forcing a user to learn as much as their use case is complex. As such, the dashboard of your dreams is just a @flow away.
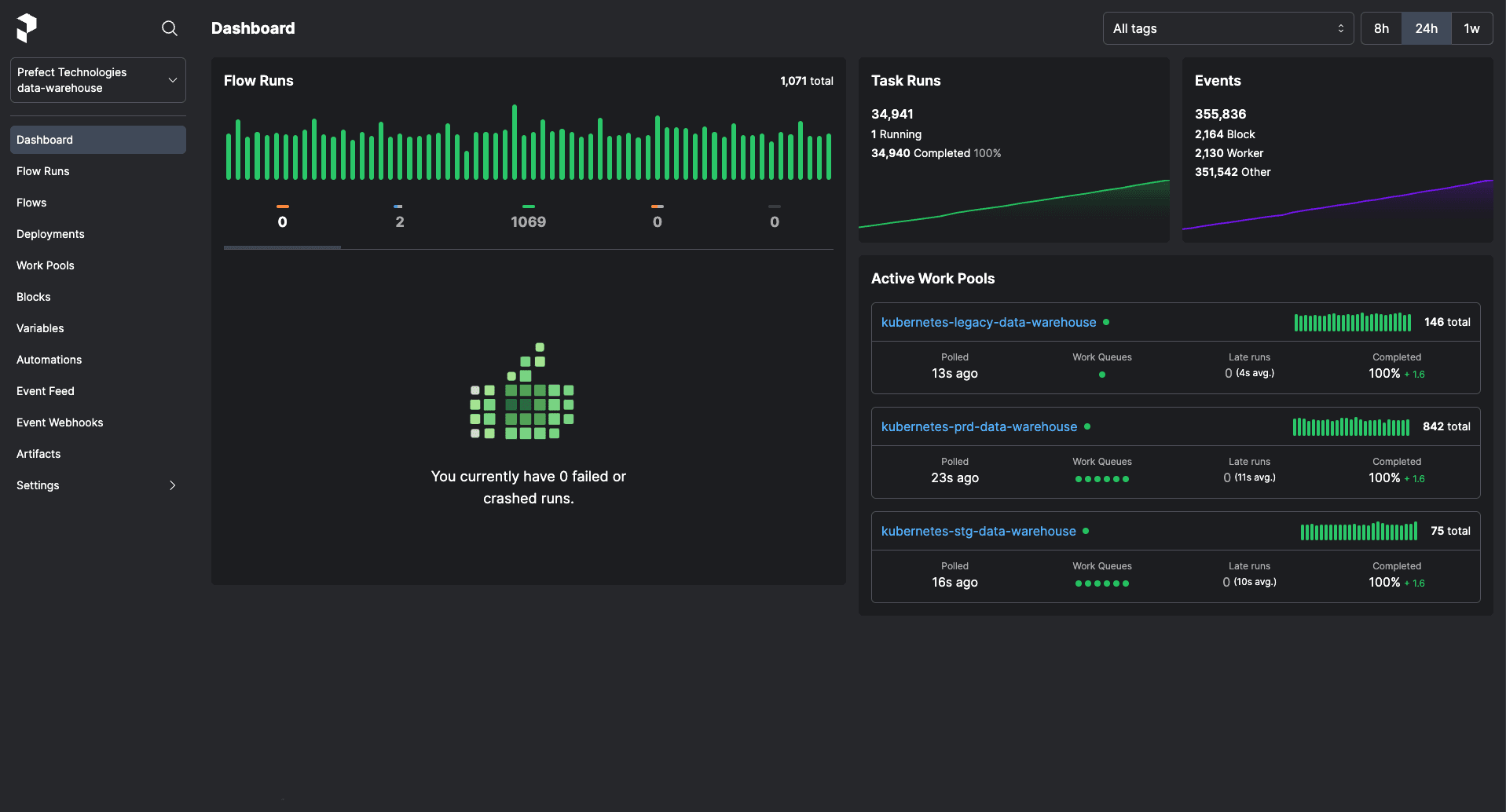
What the Flow? Turn Functions Into Workflows
Workflow orchestration is the business of executing scripts that are governed and formally observed by the core orchestration engine. This is exactly how Prefect works. You accomplish this by making your script execution a flow run - just our term for a function with an @flow decorator on it. This ensures the script and its execution are tracked, with all the gory details - parameters, state changes, results produced, metadata, and any other important information you want.
Prefect includes a number of ways to schedule your script, but the easiest is an embedded approach - orchestration aside, the decorator allows you to observe when your script already runs, potentially triggered by another service (maybe an event, maybe a webhook execution, all up to you). A key property of an observability platform: it should not matter where, when, or how your script runs - its state should always be observable. With no external servers or config changes, elevate a script to a flow - observable by Prefect’s dashboard - with imports and decorators only.
1from prefect import flow, task
2
3@task
4def say_hello(name: str):
5 print(f"hello {name}!")
6
7
8@flow(name="Hello World!", log_prints=True)
9def hello_world(name: str = "world":
10 """Given a name, say hello to them!"""
11 say_hello(name=name)
12
13
14if __name__ == "__main__":
15 hello_world(name="Will")Now, when you run your script - the Prefect engine oversees your script’s execution, and communicates metadata about its execution back to the Prefect orchestration server.
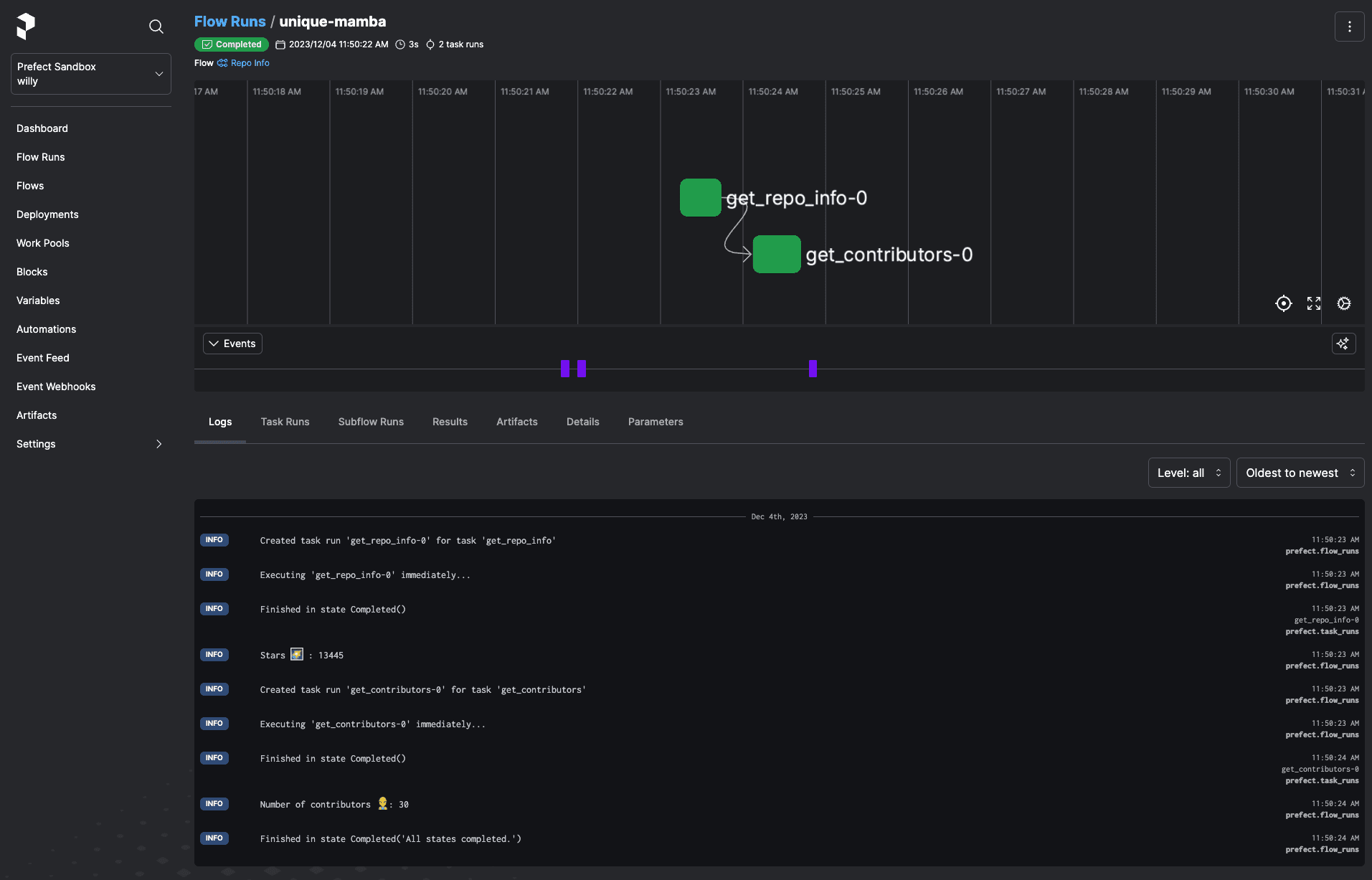
An Observability Platform for the Masses
Just like my hacky box of scripts, if flows never failed, we wouldn’t need anything more than a scheduler. Alas, flows do fail, creating the need for an observability platform, collecting all execution metadata. The platform element of observability enables you to work on failures with your team - through dependency management and collaboration.
By sending this data to Prefect Cloud, you can resolve failures faster by collaborating on them with your team, seeing a failure’s dependencies in a glaringly obvious way, easily finding AI summarized logs, and diving deeper when required with detailed event history to build context. And remember, any shared page can also be shared with your workflow’s end user - never leaving them in the dark.
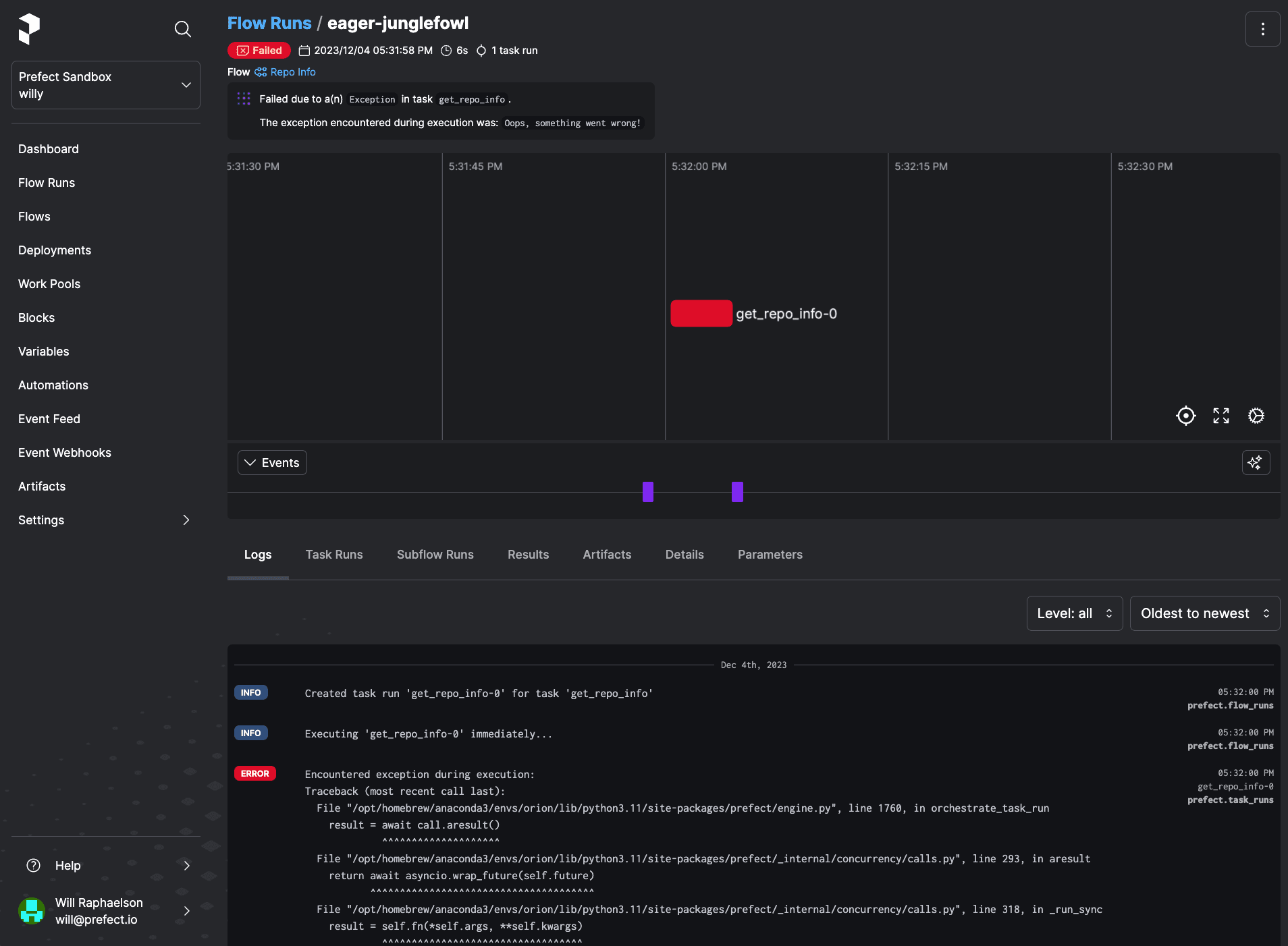
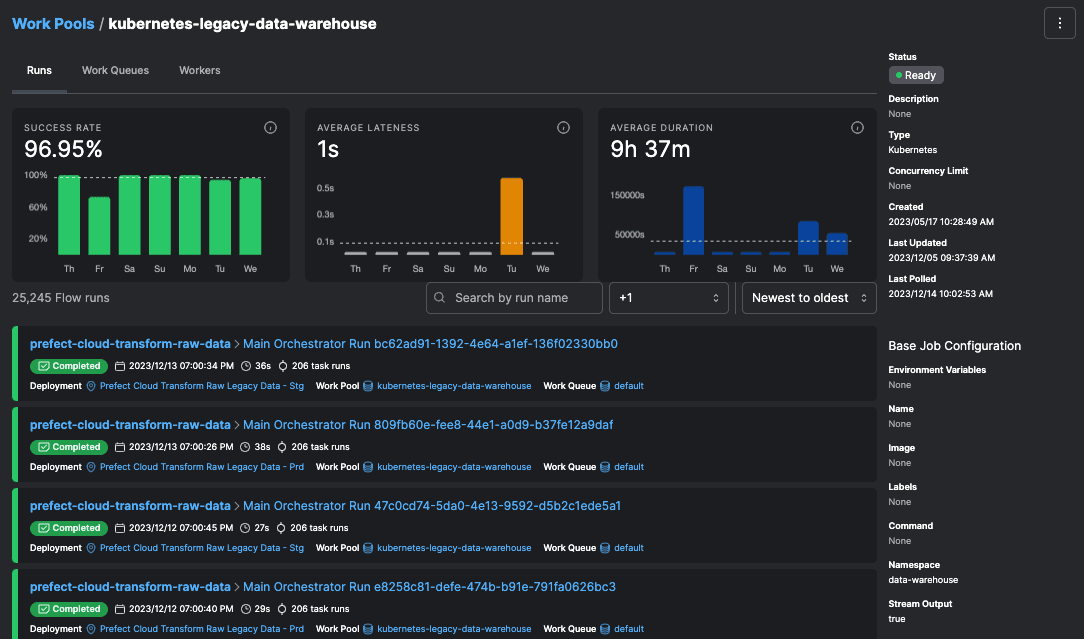
Over time, your Prefect Cloud instance, specifically your flow runs page, becomes a historical record of sorts. An observability platform stores history of the performance of all the workflows you support, helping your team understand weak spots in the stack and common failure modes.
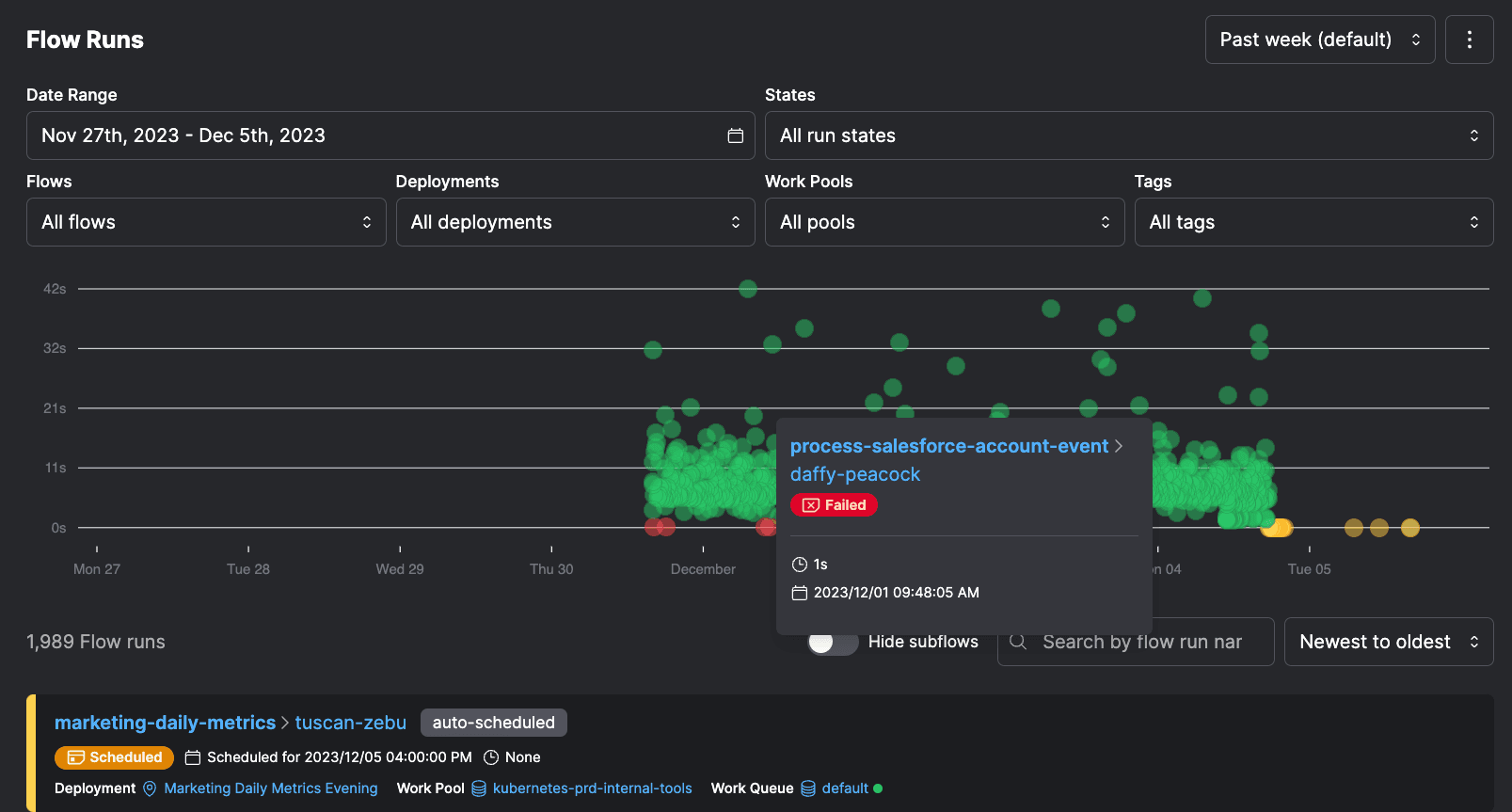
Prefect automatically extracts patterns from these execution events, distilling events into metrics around average completeness, duration, and lateness to give your team a single source of truth around system status - all with minimally invasive config and code changes.
Dedicated Workflow Observability 🤝 Automated Orchestration Action
Each of my hacks back in the day - for retries, failure notifications, and concurrency controls - suffered from the same cardinal sin: the workflow was attempting to observe itself.
Because the monitoring was running in exactly the same process the workflow was running, failure of the workflow meant failure of the monitoring logic. There was no separation to monitor actively crashing workflows.
The "platform" part of "observability platform" means the monitoring is independent from workflow infrastructure. When workflow infrastructure failures, you should still see notifications, historical performance, and logs.
A separate, dedicated control plane for workflow observability is essential to resilient workflows, and Prefect makes the developer experience of observability delightful.
Retries on flaky scripts
Retries are a key tenant of observability, that should just be an argument away. With Prefect, this is an argument passed to the @flow decorator.
1@flow(retries=3)
2def main():
3 do_thing()Notifications on workflow failures
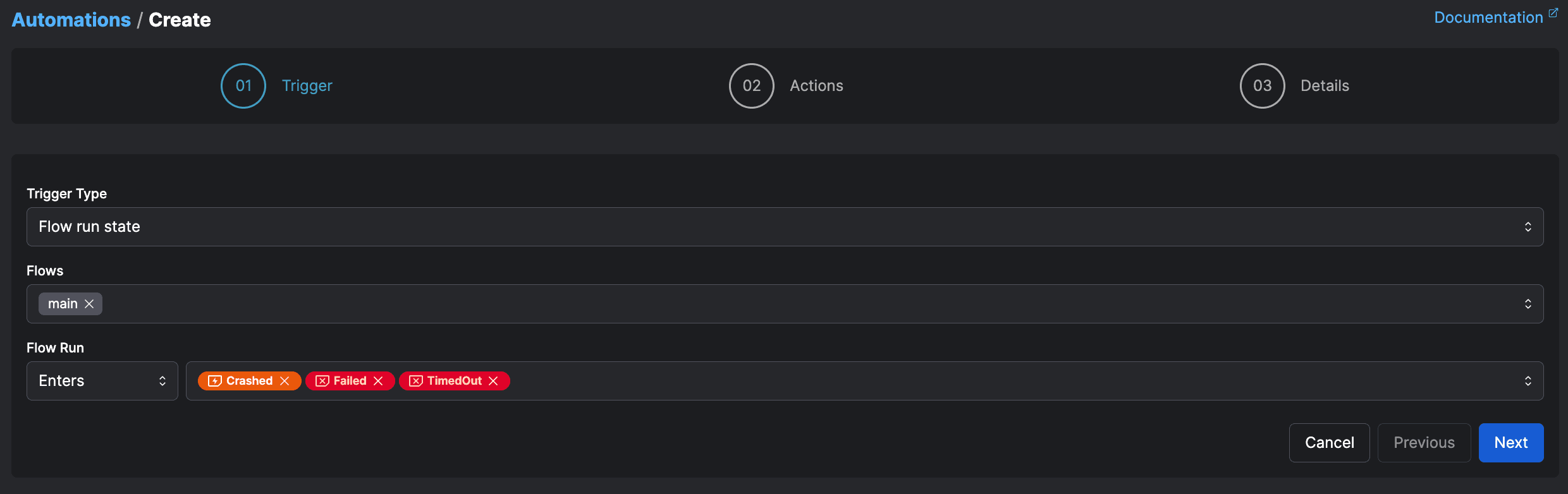
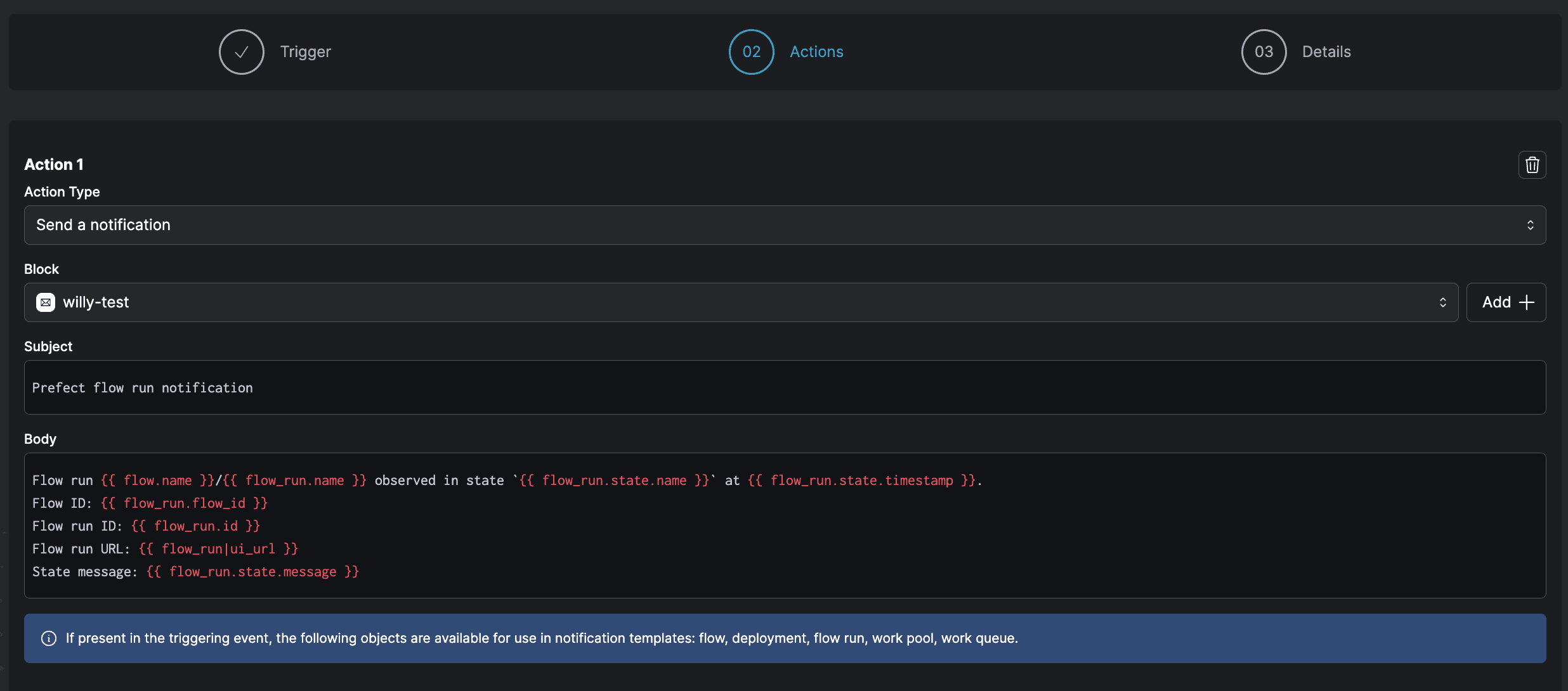
The notifications tenant of observability must live in a separate plane, constituting the platform aspect, either UI or code-first. Automations in Prefect run whenever the workflow states you care about are observed, and notify you in your platform of choice like Slack, configured either in UI or in code.
Concurrency controls
Running tasks in a workflow concurrently is a key scalability feature of orchestration systems. This is where orchestration and observability intersect - with proper concurrency, observability becomes easier with fewer infrastructure errors.
Simple, context manager-based concurrency slot occupation and release.
1@task
2def process_data(x, y):
3 with concurrency("database", occupy=1):
4 return x + yThat's not all folks
Workflow observability via embedded orchestration is just the beginning. The true power of Prefect lies in combining observability with automated orchestration action taken on your behalf. Prefect’s orchestration layer in combination with the observability platform enables truly actionable information on your workflows - to triage and scale them. Trigger flows based on events with automations, ensure strict enforcement of data dependencies, and provision a self-healing workflow application platform with infrastructure integrations. Deploy to production faster, more reliably, and share your work with your happier stakeholders.
Try Prefect Cloud for free for yourself, download our open source package, join our Slack community, or talk to one of our engineers to learn more.
Related Content








