
Our Second-Generation Workflow Engine
Today we’re introducing Prefect Orion, our second-generation workflow engine. Orion is the result of nearly two years of research, design, debate, and exploration into the challenges of negative engineering. With a focus on dynamism, developer experience, and observability, it is a strong break with the legacy approach to workflow management. Orion's mission is simple: you should love your workflows again.
Orion is the API that will power the future of Prefect, and its alpha is available today as an open-source technical preview. We expect to release Orion in early 2022 as Prefect 2.0. For more on Orion's release schedule, please visit our FAQ.
What makes Orion special is its core: the modern data stack’s first dedicated orchestration engine. Even its name - ORchestratION - is a nod to this critical role. As an orchestrator, Orion is a governing rules engine and source of truth for code transitioning through a variety of canonical states, such as SCHEDULED, RUNNING, and COMPLETED. As an arbiter of state, Orion’s job is to help dependent code run to completion or, in the case of unexpected failure, intervene to ensure that appropriate steps are taken. It does so through another Prefect innovation: a dedicated orchestration API. A few years ago, our patented Hybrid Execution Model enabled the first-ever separation of workflow code from workflow metadata; the Orion API takes that idea to the next level by separating the orchestration engine from the code being orchestrated.
The opportunities created by a remote orchestration API are boundless. By starting with a strongly-defined model for tracking the state of executing code, we were free to reinvent how developers interact with orchestration to solve many of the common frustrations with legacy workflow management systems. The most obvious consequence of moving the engine behind an API is that Orion becomes language-agnostic: any client in any language will be able to request orchestration, and Orion will deliver it in a well-structured way. Once registered with the API, the client is free to execute code however it prefers: a Python client could checkpoint data running through a complex machine learning pipeline, an R client could validate dataframes, a JavaScript client could retry critical user actions; a Kubernetes client could report an infinite stream of health checks — possibly all in the same workflow!
Over the last decade, there has been a misleading push toward “workflows as code.” While this is certainly an improvement over defining workflows in, say, XML, it still requires developers to completely rewrite their code to match their orchestrator’s expected data structures or vocabulary. In fact, one of the things that originally made Prefect so popular was that our functional Python API did much of that translation automatically, minimizing developer burden. Orion inverts this approach and embraces “code as workflows,” acknowledging that whenever an engineer writes code, that code is already the best possible expression of their workflow objectives. Any subsequent modification or translation is a cost borne by the engineer to gain orchestration features, and increases the risk of unexpected failures caused by not fully understanding the orchestrator's abstractions or inner workings. By removing as much of that translation layer as possible, we eliminate a major source of negative engineering frustration.
This motivates another key innovation in Orion’s approach: it can be adopted incrementally and additively, without modifying existing code. You don’t need to rewrite your entire workflow as a DAG to take advantage of Orion; you can pick and choose only the individual pieces of it that you want to be registered with the orchestration API. For example, maybe there’s just one flaky function that you want Orion to retry on failure; or maybe you want to use Orion only for caching the output of particularly expensive calls; or maybe you want Orion to schedule your script, but not to orchestrate it; or maybe you just want to share the history of your runs in the Orion dashboard. The more you adopt Orion, the more helpful it can be; but if only a piece of it is useful, then you’re never required to use more than that piece. We've taken this approach to such an extreme that you don't even have to be running an Orion server to benefit from persistent Orion orchestration.
In order to achieve these ambitious objectives, we identified three critical items that Orion must deliver:
- Dynamically registered, DAG-free workflows
- A seamless developer experience from test to production
- A transparent and observable rules engine
In this post, we'll go into each of these objectives in some detail, and we'll follow up with more technical dives in the future. The tangible result of this work is one of the most powerful but easiest orchestrators you'll ever try - even in technical preview form. We hope Orion is the first workflow system you actually love to use.
Dynamic workflows: you can't teach an old DAG new tricks
Prefect represents the cumulative experience — and frustrations — of thousands of data engineers. Starting with just twenty people two years ago, Prefect's online community has swelled to nearly 10,000 members and is growing faster than any other active data community, thanks to a clear focus on positivity, support, and our willingness to declare that the emperor has no clothes: there simply must be a better way to build data workflows. As a result, Prefect powers some of the largest and most sophisticated companies in the world - and many more that will achieve that status soon.
As Prefect has matured, so has the modern data stack. The on-demand, dynamic, highly scalable workflows that used to exist principally in the domain of data science and analytics are now prevalent throughout all of data engineering. Few companies have workflows that don’t deal at least in part with streaming data, uncertain timing, runtime logic, upstream dependencies, dynamic mapping, dataflow, complex conditions, versioning, subgraph retries, or custom scheduling, just to name a few.
This complexity has resulted in a significantly compromised developer experience when it comes to workflow management. As companies rapidly adopt new technologies, an increasingly frustrated class of workflow engineers are trying to figure out how to carefully dumb-down their companies' workflows to make them compatible with the limited feature set of legacy orchestrators. Testing and observability quickly become secondary concerns to the confounding and time-consuming exercise of just getting the workflows to run.
As we investigated these dual problems in the workflow space — the growing complexity of the workflows themselves and the commensurately poor developer experience — one culprit kept surfacing over and over: the DAG.
DAGs are an increasingly arcane, constrained way of representing the dynamic, heterogeneous range of modern data and computation patterns. They force modern engineers to express their objectives through a lens that rose to workflow popularity almost three decades ago, when it was reasonable that a single node would monitor a small set of well-structured tasks. As reality continues to march further from that expectation, there is probably no structure in the modern data world that has become more synonymous with developer frustration than the DAG.
But DAGs are "just good enough" for the simple batch processing jobs and regular schedules that have characterized data engineering for the last decade. It's only recently, as data engineering itself as matured, that these limitations have become apparent. For Prefect users that want to dynamically spin up thousands of analytic tasks and rerun parts of their workflow in response to downstream validation failures, DAGs are not only not good enough, they're "not even wrong."
By removing the need to pre-compile a data structure that fully represents the execution of the workflow, users gain incredible freedom. Since workflow discovery and execution are now equivalent, native code can be run side-by-side with fully orchestrated workflow steps. Workflows can be modified or even generated in response to runtime conditions or streaming events. Complex conditions that require convoluted DAG structures can be represented with simple if statements. Stateful objects can be shared among tasks or, conversely, remote execution environments can collaborate to bring a single workflow run to completion. Here are a few more examples of what this enables:
- Use native control flow like if statements or for and while loops inside your workflows
- Generate new tasks or entire workflows in response to streaming events
- Use complex branching logic that can even depend on runtime conditions
- Create triggers that respond directly to the states of upstream tasks
- Run infinitely-long workflows or monitoring processes
- Start downstream tasks before upstreams have finished
- Re-run parts of the workflow in response to failed validation checks
- Share stateful objects like database connections between tasks
- Generate infinitely-nested subflow structures for modularity
- Have multiple executors or runtime environments collaborate to fulfill the same workflow
- Workflows are free to evolve over time without reregistration or orphaned tasks
And on and on. When we remove the forced DAG and embrace "code as workflows," the only caveats for what users can do are the limitations of their preferred language.
It may take some time for developers that are used to DAG-based systems to fully realize the potential that Orion represents. And even developers running relatively straightforward, DAG-compatible workflows can benefit enormously from the developer experience enhancements and iterative fluidity that our new approach unlocks.
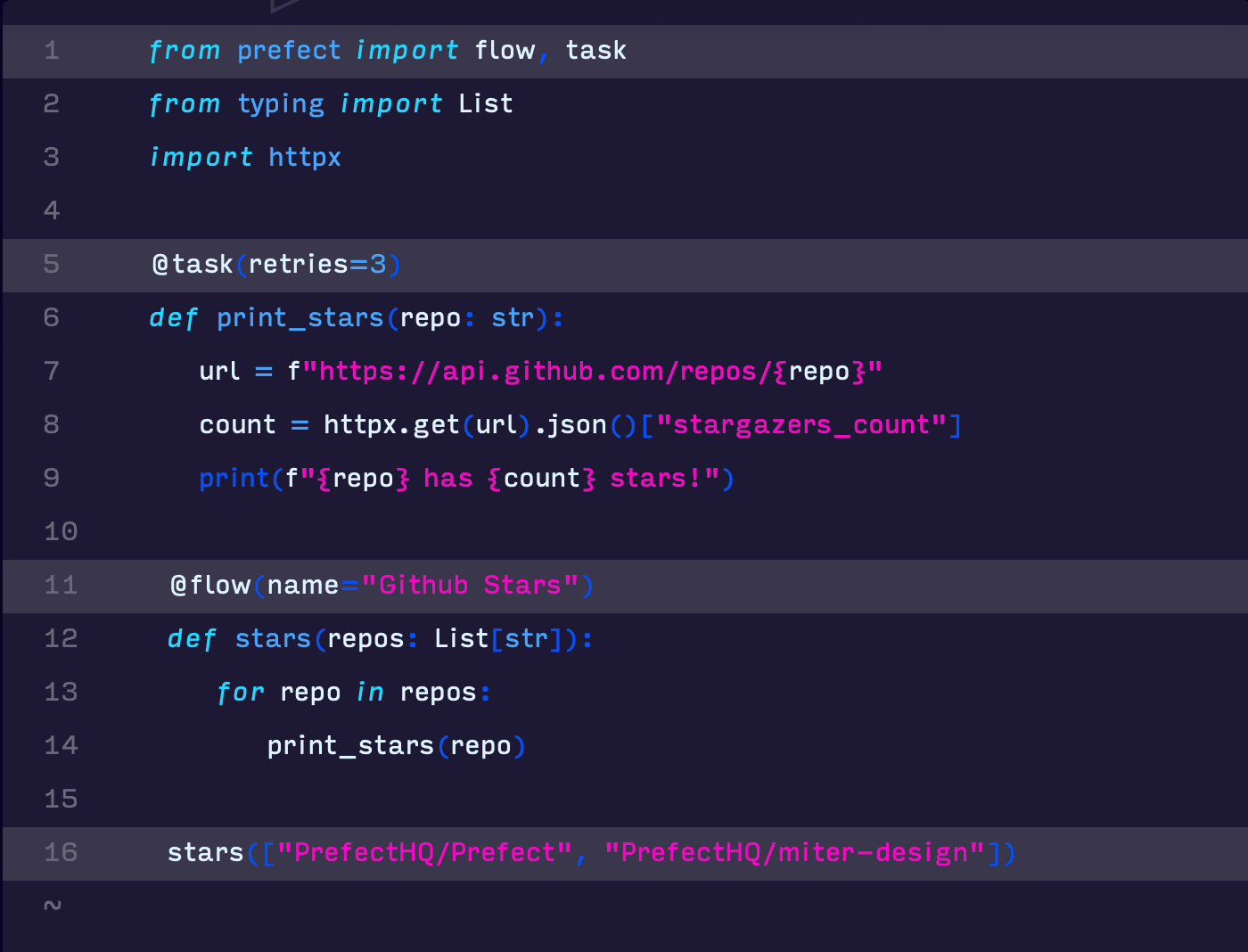
Developer experience: code as workflows
By embracing "code as workflows," Orion can deliver a developer experience that is as good as writing native code - and maybe slightly better, thanks to simple orchestration.
One of the ways we achieved this was by ensuring complete parity across the sandbox, testing, and deployment phases of building a workflow. To run an Orion workflow, you simply call() it. There are no special entrypoints or CLIs that users must learn, no "test modes" to enter, no orchestration contexts to supply. You don't even need to start an Orion server. The workflow and all its tasks will be dynamically registered against an ephemeral but persistent API.
This means that when you run an Orion workflow, it is running with exactly the same machinery as it will when deployed at scale, subject to your computer's operating environment. You can take advantage of this in a few interesting ways:
- Use your favorite interactive debugging tools, from print statements to breakpoints
- Unit tests are as easy as calling a function and examining its output
- If a task had an error in production, you can download the upstream states that were provided to it and replay the task locally to interactively debug a deployed application (watch this space for more information on the Prefect IDE)!
The "ephemeral Orion API" is a big part of what makes this possible. While Orion's orchestration engine is delivered as an API, that API can be generated locally whenever a workflow needs access to orchestration functionality, even without deploying a stateful Orion server. By default, these ephemeral APIs will inherit your global settings and even persist data into your globally persistent store. As a user, this means that running your flow in an interactive session — without spinning up Orion — can be exactly equivalent to running against a fully-managed Orion deployment. You can even spin up the Orion Dashboard after running your flow to see the results of your interactive session.
Ephemeral Orion is extremely useful for a variety of interactive use cases, such as testing and development, running workflows in CI, serverless execution, and more. When it's time to hand your workflows to the API for automatic scheduling and execution, you create a Deployment: a description of where your flow's code lives and how to run it. This allows a stateful Orion server and its related maintenance services to work with your flow automatically, making sure it runs on schedule and monitoring its progress remotely.
None of this would be possible without a renewed commitment to building on established standards. Orion does not require users to learn new vocabularies, data structures, or hierarchies. It is designed to maximize use of the tools you already know and love, with little or no adaptation required. This is part of our product objective to "meet users where they are" and support incremental adoption, and we gain enormously by standing on the shoulders of giants:
- Pydantic unlocks best practices for type validation, coercion, and enforcement. If your task requires a datetime, simply annotate its parameter using standard Python typing and Orion will take care of the rest
- FastAPI ensures that Orion maintains a beautiful, OpenAPI-compliant API and unlocks testing and inspectability from an wide ecosystem of tools
- RRule scheduling - which was first introduced to us by a Prefect community member! - means that Orion flows support all of the complex scheduling rules behind the .ics iCalendar standard, in addition to old standbys like cron and microsecond intervals. Yes, that means you really can export a schedule from Google Calendar and load it right into Orion.
- Sqlite compatibility enables a "batteries included" experience for new users before they upgrade to Postgresql.
- Native asyncio (and anyio) support means that Orion supports the entire spectrum of Python concurrency models
- An updated executor model better supports the idiosyncratic configurations of systems like Dask, allowing deeper integrations and control
- Even our documentation is improved by being built on emergent Python standards like mkdocs-material, of which Prefect is becoming a sponsor
There is a trend in the data space that is leading to a flood of pairwise proprietary integrations between various services and platforms. With Prefect, this isn't necessary. By leveraging standards we natively integrate the power of the ecosystem without any duplication of effort. If your tools embrace pydata standards, then they'll work great with Orion. More broadly: if Python can write it, Orion can run it.
The rules engine: orchestration as a service
Completely dynamic workflows and an emphasis on universal developer experience are hallmarks of Orion's design, but the heart of the system is its orchestration engine and API.
In order to deliver orchestration via API, we first had to figure out what, exactly, orchestration is. This turns out to be a slippery definition to pin down. Everyone seems to know orchestration when they see it, but orchestrators themselves appear very confused about whether they are task schedulers, data lineage tools, or pipeline monitors.
In fact, orchestration is none of those things - though it may integrate with them well. An orchestrator's job is to enforce rules on the way code is executed, without interfering in the execution itself. Examples of orchestration functions include:
- Task 2 must wait for task 1 to complete before it runs
- A task may retry up to three times on failure
- A task should never retry if the infrastructure it runs on crashes
- Only 10 tasks that talk to a database can be running at any time
- Tasks should start at 9am on weekdays
- Task data should be cached for one week
- Tasks should be run on specific infrastructure
- If data validation fails, rerun part of the upstream flow
- 15-minute SLAs should be enforced on late workflows
- Tracking the inputs provided from one task to another
- Rendering artifacts produced by tasks
- etc.
Notice that in all of these examples, words like "Task" are simply placeholders for executable code. This is important: in a real sense, the orchestrator doesn't care whether a task computes the sum of its inputs or trains an entire machine learning model; its job is to make sure that no matter what the task does, it runs if it's supposed to with whatever resources or data it requires to do so.
Prefect uses states as the vocabulary of orchestration. Here, for example, are the possible states and state transitions of a workflow:
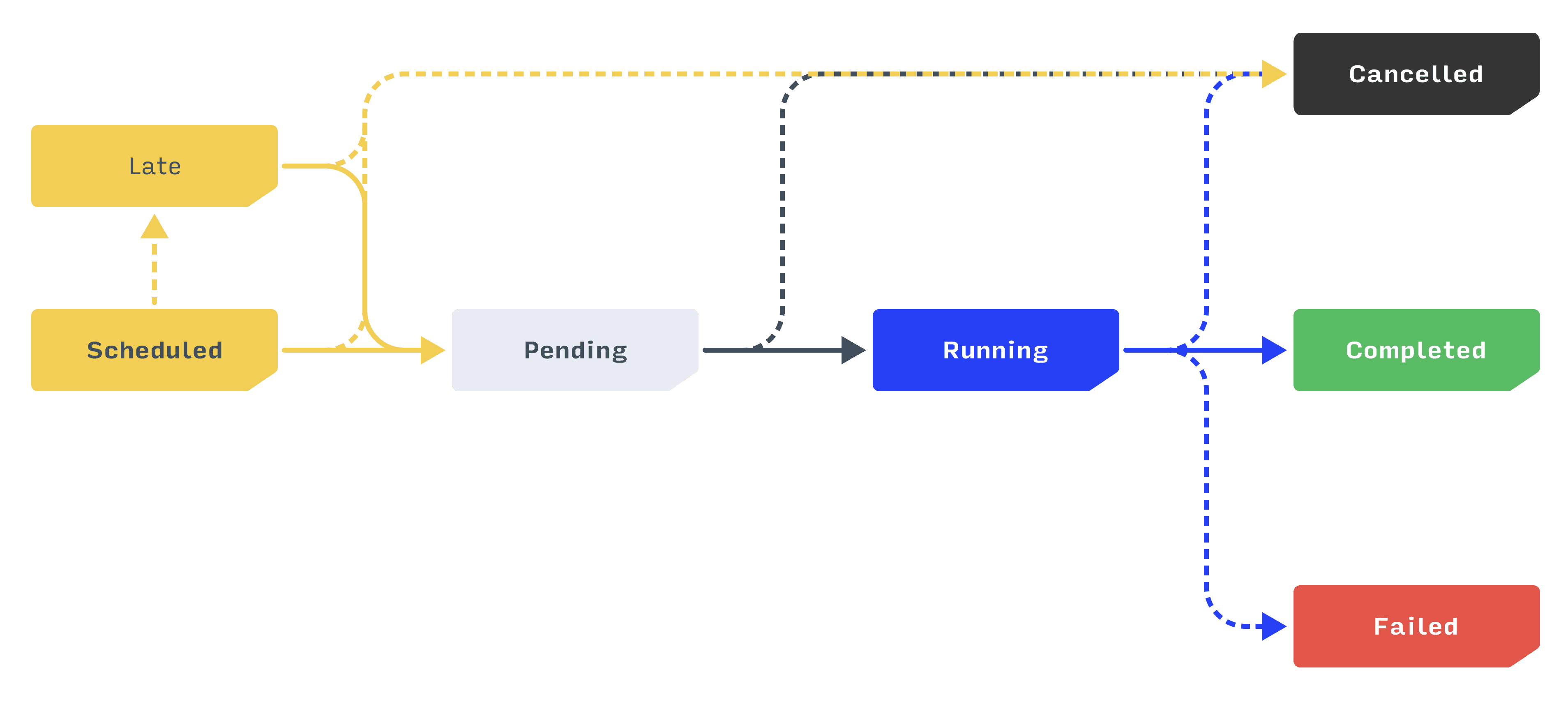
Orion defines "orchestration" as the rules governing transitions between states. This is how we deliver orchestration over an API: remote clients indicate the state they want to transition into, and the orchestrator uses all available metadata to determine if the transition is allowed, must be modified, or should be rejected entirely.
For example, say a workflow is Scheduled for 9 am. Any attempt by that workflow to enter a Pending state will be rejected by the orchestrator until the scheduled time is reached, because that's an important orchestration rule (note: users can always apply any state manually). If an orchestration policy was defined that includes limits on concurrent workflows, then the orchestrator might continue to block entry into a Running state until those conditions are met. However, once the transition to Running is permitted, control is returned to the remote client for code execution.
To the extent that they support this level of control, contemporary workflow tools encode these ideas in black-box state machines. Thanks to this clear formalization of orchestration, Orion's rules are atomic, easy to parse, and completely transparent. Their source code is so readable, it's self-documenting. Whenever a client requests orchestration from the API, Orion runs the proposed transition through the rules engine and can produce a clear report on exactly what happened, and why. In this way, Orion becomes the unambiguous source of truth for workflow orchestration.
Consider the equivalent diagram for tasks, which reflects a greater number of possible orchestration states:
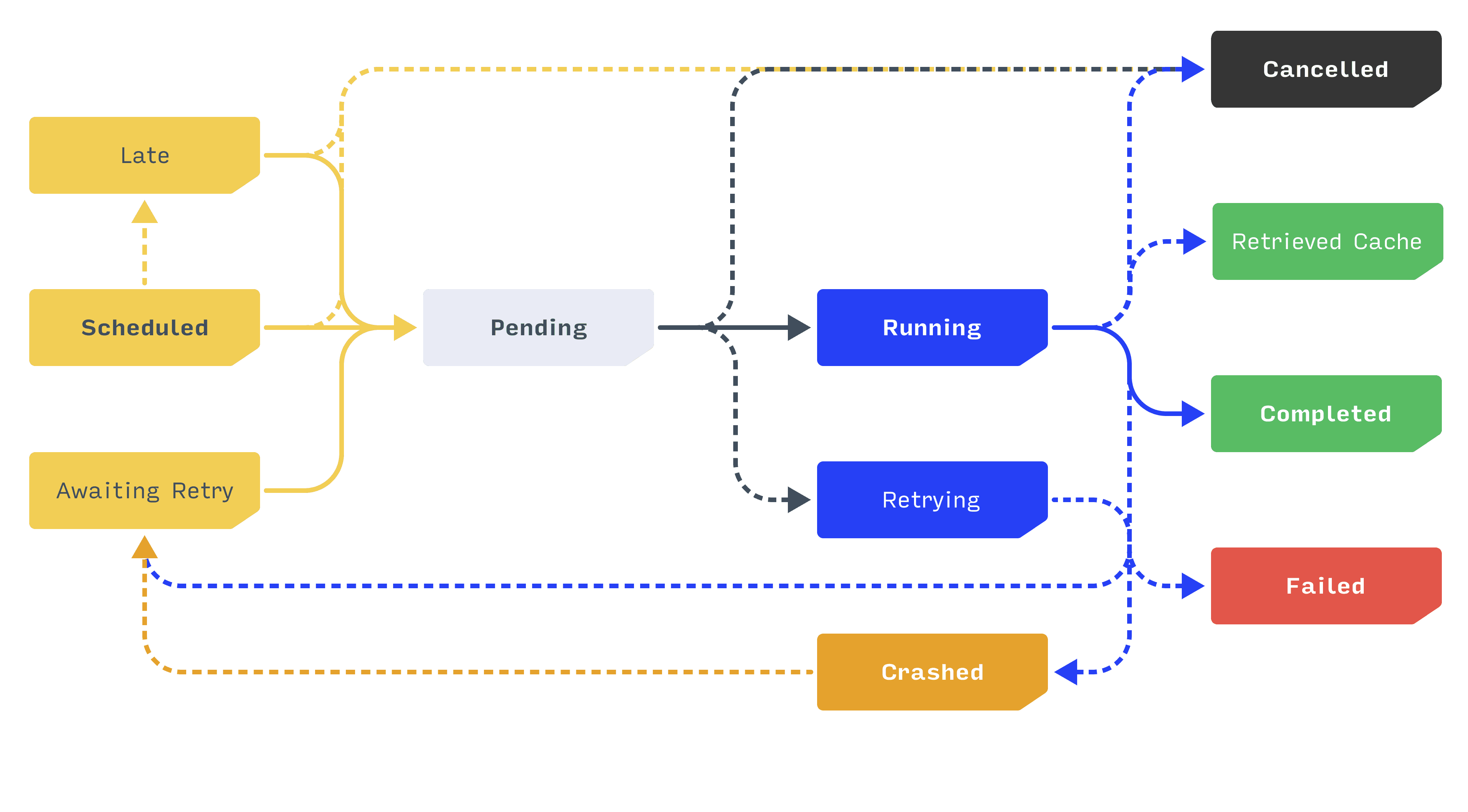
This diagram helps illustrate some interesting rules that Orion makes easy to implement:
- When a task attempts to enter a Failed state, the orchestrator examines the number of times it ran and the number of retries it is allowed to have. If appropriate, it rejects the Failed transition and instructs the task to Await Retry instead. The client will respect this instruction and retry the task appropriately.
- When a task attempts to enter a Running state, the orchestrator checks if it was configured to use cached outputs and, if a matching value is found, moves it directly to a Retrieved from Cache terminal state. The client will respect this instruction and move directly to the next task, using the output provided by the orchestrator.
Thanks to this framework, we have been able to implement complex orchestration logic in a surprisingly simple way.

But wait, there's more!
As a product-led company, Prefect is grounded in user research and feedback. The vast majority of enhancements, feature requests, and frustrations that we've collected over the last two years are directly resolved by Orion.
This freedom to innovate shows up in unexpected places. Not only does Orion feature a brand-new UI called Dashboard, but before we wrote a line of code, we built a design system optimized for rendering workflow-related information. This open-source system, called Miter Design, prioritizes clear and accessible communication of state-related details and embraces our constellation metaphor. The UI itself includes innovations like radial workflow schematics, soundwave failure graphs, and a rapid filter mechanism for custom queries and dashboards. Because color is one of our major metaphors for workflow state, we have included a variety of themes for colorblind users and new iconography for improved communication. And above all else, the new Dashboard is fast.
Future enhancements to the Dashboard will include the ability to interact with Orion without code. For example, you'll be able to create, deploy, schedule, and run flows simply by telling Orion where they are. We are exploring a "Prefect IDE" to enhance the experience of interactively debugging production-deployed workflows even further.
We have also rethought how workflows and data are persisted. While of course users remain free to write data wherever they like, it is frustrating to have to provide, for example, cloud storage credentials to every workflow. Furthermore, any error encountered when serializing data - such as a poorly configured location - bubbles up and fails the workflow, when in fact the workflow itself had no issue. Therefore, Orion introduces a new Data API - a configurable way to persist arbitrary results. This separation of execution from data checkpointing means that flows can complete successfully even if their persistent storage location can't be reached, and users can completely identify, troubleshoot, and configure such errors from the Orion UI.
The future of Prefect
Orion represents the future of Prefect's orchestration engine and API. It will power a new generation of open-source, self-hosted, and commercial Prefect products. We are releasing it today as a technical preview because it has achieved its primary design objectives, but it still has a ways to go. In the coming months, you will see Orion undergo rapid changes as it approaches a stable release in early 2022. At that time, we will release Orion as Prefect 2.0, replacing both Prefect Core (1.0) and Prefect Server as our default orchestration engine.
Prefect 1.0 is our battle-tested, production-ready workflow engine. Prefect Cloud customers have used it to execute nearly half a billion tasks just this year, and our open-source users have run at least an order of magnitude more. Its API has remained relatively stable - and almost completely backwards compatible - for almost two years. For these reasons, as a reflection of its maturity, Prefect Core will be promoted to 1.0 in the near future. Prefect 1.0 will remain fully supported by the Prefect team for at least one year after Prefect 2.0 is released.
As Orion nears release, we will produce a complete upgrade guide from Prefect 1.0 to Prefect 2.0. Migration will be easy, as Orion is even more lightweight than 1.0, and we are exploring a variety of ways to automate or assist in the process.
Please note that Orion is being released as a technical preview; you may consider it the first alpha release of Prefect 2.0. Its core design objectives have been met, but some of its features are still in development. It is ready for the community's feedback but we do not recommend using it in production yet.
Orion represents a fully-realized achievement on three dimensions: fully dynamic workflows; an uncompromised developer experience; and an observable rules engine. We can't wait to see what you build.
Happy engineering!
Related Content








