
More Memory, More Problems
Beginning in March, Prefect Cloud saw a significant increase in volume and traffic driven by both new user growth as well as existing teams scaling up — by most measures we were doubling approximately every two months. This is great! But unsurprisingly this level of growth comes with a whole host of challenges for our team, especially when it comes to service reliability and resiliency.
Importantly, some of our customers suffered from service interruptions related to the issues described here. First and foremost, we are incredibly sorry for the negative impact and stress these incidents caused. We are committed to doing better.
Sometimes configuring a database at scale can seem like a dark art. While the Postgres documentation is fantastic, there are no hard-and-fast rules for tuning given the diversity of workloads out there and much of what we learned came from sparse references and experimentation. We hope that compiling our findings will help future engineers get ahead of the challenges we faced — if you want to skip the narrative, feel free to jump ahead for a summary of our findings.
The Context: Scaling Up
In anticipation of continued Prefect Cloud growth, we accelerated our plans for a proactive scale-up of our backend. The first phase of this took place in the first two weeks of April, during which we vertically scaled our primary Postgres 14 instance (running via CloudSQL in GCP).
The second phase of this work involved partitioning our most heavily used tables; large tables can exhibit poor query performance and latency due to indexes that are too large to fit into memory and unreliable table statistics. Partitioning a table essentially breaks the table up into many smaller virtual tables that the query planner can take advantage of, helping to avoid these issues. At the time of our decision, our fastest-growing table had 400 million rows and we expected it to have over 1 billion rows by the time the partitioning work would be completed. In order to partition our tables without incurring downtime, we rolled out our changes incrementally over several weeks (we’ll share more detail in an upcoming post). This allowed us to incrementally update our application to handle partitions, monitor for expected performance improvements, and adjust the plan as we went along.
We felt confident in our partition calculations and were optimistic that we’d begin seeing performance gains very soon…
The Investigation: High Memory Utilization
All the while that we were rolling out table partitions, our memory usage remained relatively constant and high. This was especially surprising because we had just vertically scaled the database, but it was difficult to understand the root cause because of the overhead of the in-flight partitioning work. It was of course also possible that our math was wrong and the partitions were inefficient, or worse, that the memory usage was an independent problem altogether. We remained confident and focused on rolling out the last two table partitions before reaching any definitive conclusions.
On April 28th, 2023 our hand was forced — during a particularly bursty period of traffic, the database unexpectedly restarted with an out-of-memory (OOM) event when memory utilization hit 90%.
The first thing we observed was that memory utilization roughly correlated with the number of active connections — this isn’t unique or surprising, as individual connections do have a memory footprint. To reduce memory pressure we scaled down our services to reduce the number of connections at the cost of increased API latency. Connections shouldn’t take up more than a few hundred megabytes of memory at most, and we needed to eventually free up almost 100GB of memory to feel long-term stable — this is all to say that we knew we were only helping the system on the margin, and reducing the number of connections wasn’t a true solution.
While still in the midst of our investigations, on May 1st, 2023 the database restarted a second time due to another OOM event. It was painfully clear that we couldn’t wait for the partition work to resolve this issue (and even that wouldn’t be guaranteed) — something needed to be done immediately. We began iterating through various Postgres configuration options such as shared_buffers and work_mem to try and see if any moved the needle significantly (our services are able to handle anticipated DB restarts without disruption). All the while we were collectively trying to construct a meaningful theory for why any of this was happening - there was clearly a missing piece of the puzzle. Maybe it was a silent config change in our vertical scale up? Maybe the partition work was quietly introducing something nefarious? The team floated and tested many hypotheses.
It was in the midst of this experimentation that a new theory emerged — each webserver that communicated with the database managed its own in-process connection pool. In the absence of a pod restart, the connections within each pool were recycled every 2 hours. It was not out of the realm of possibility that these connections might be accruing an increasingly large cache that needed flushing. This seemed all the more likely given the relatively tight correlations we were seeing with scale ups / scale downs and large changes to memory utilization.
We updated our connection pools to recycle their connections every 10 minutes and quickly released the change to prod. Coincidentally and seemingly unrelated, we had noticed that an entirely separate database used for our events system was not being traced properly. So in addition to the pool recycle change, we released a small change that ensured our SQLAlchemy instrumentor was turned on for all engines (essentially replacing the line SQLAlchemyInstrumentor().instrument(engine=engine.sync_engine) with SQLAlchemyInstrumentor().instrument() ).
We released these changes and were all on the edge of our seats, monitoring our dashboards to see if we could discern any change. It didn’t take long to see something noticeable:
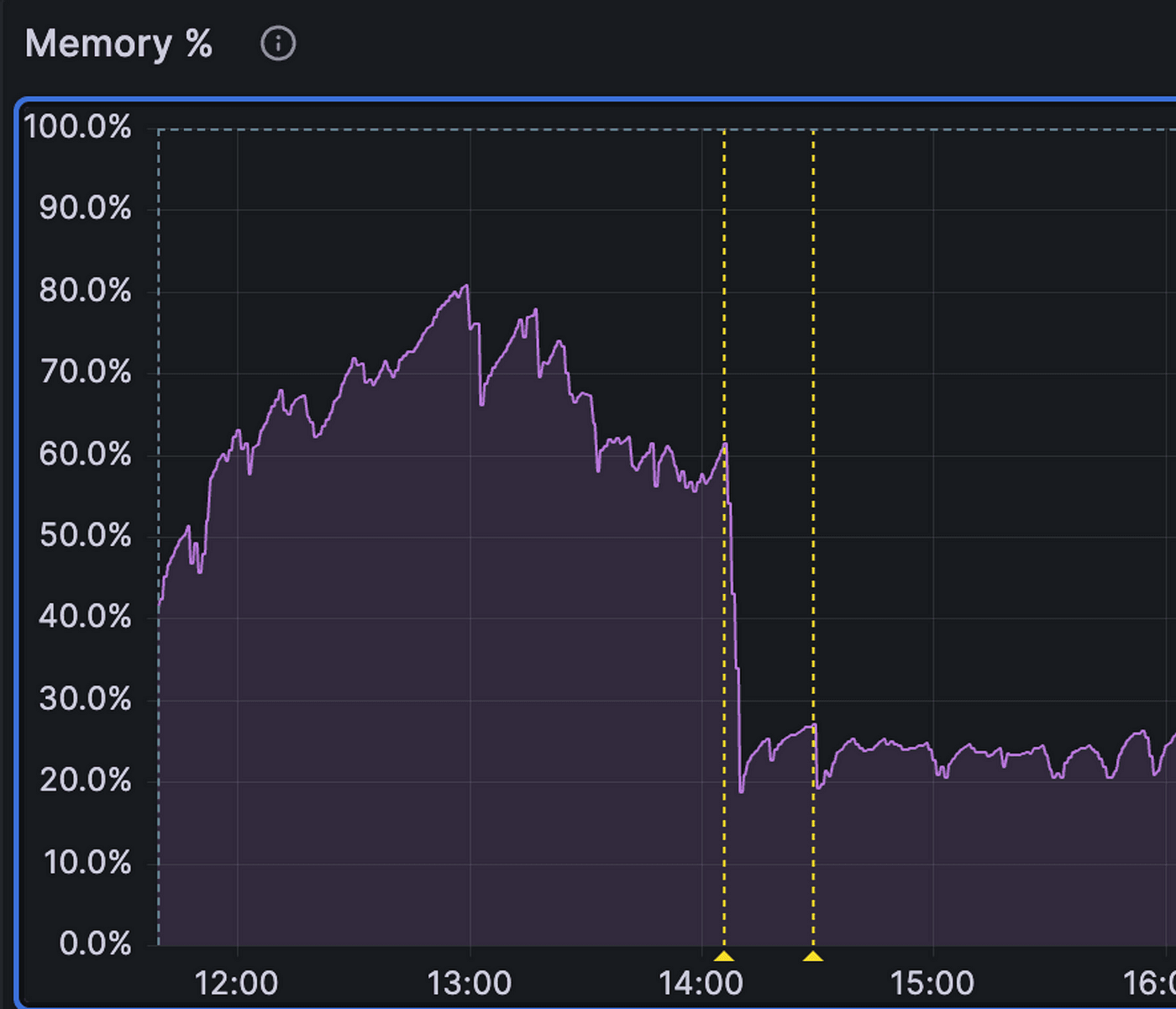
It seemed like we had hit the jackpot! The database seemed healthier than ever — we carefully scaled our services back up with almost no effect on memory. On top of that, API latency was better than it had been in weeks. Despite feeling less acutely stressed, we remained unsatisfied with this empirical solution that lacked an airtight explanation; we began trying to refine our original theory to explain why this seemingly simple change brought us back to the healthiest state we had seen in weeks. However, we couldn’t seem to break past the hand-waving phase to anything more specific and testable…
The Twist: Load-Bearing Comments
As we reflected on the prior few days and were organizing our insights, we noticed a curiosity - a different database that manages account configuration saw an unprecedented increase in received bytes (an increase of almost 400%) at exactly the same time that our primary database recovered from its memory woes. This increase wasn’t inherently concerning as this database doesn’t serve complex workloads, but it was interesting and was not easily explained by our current story.
It turns out that enabling SQLAlchemyInstrumentor globally for all engines has the effect of adding comments to every query, for example:
1SELECT *
2FROM auth.account
3WHERE auth.account.id IN (%s)
4
5/*db_driver='asyncpg',db_framework='sqlalchemy%%3A0.34b0',
6traceparent='00-93d35b06052db659c4eb5f5be2db2548-a48d7cb6e8de48f7-01'*/Because queries to our account database were generally small, this had the effect of increasing query size (in bytes) noticeably. You might ask: why is this relevant? We soon discovered that when we explicitly turned comments off across all engines, memory in our primary database began increasing back to the problematic levels.
This initially made no sense - production-grade tracers shouldn’t have that much impact on performance! We then remembered - we had seen this once before. After we successfully partitioned our events database many months back, we found that executing the exact same prepared statement six times in a row resulted in an indefinite hang on the sixth execution. Adding a unique comment (such as a trace ID) to each execution prevented the hang from ever occurring. This is because Postgres computes a “generic plan” (a plan independent of parameter values) on the sixth execution of the same prepared statement and caches it for future use - but generic plans are typically very costly for queries over partitioned tables (hence the hang). By default, Postgres uses heuristics to decide whether to use the generic plan vs. a custom plan but those heuristics don’t always work.
And this was the final piece of the puzzle.
The Resolution: Configuring plan_cache_mode
Ultimately, here’s what was happening:
- The asyncpg driver for SQLAlchemy prepares every statement
- After seeing the same prepared statement 5 times, Postgres creates a “generic plan” that is then cached for future use
- Generic plans for prepared statements do not take into account specific parameter values and are therefore costly for queries over partitioned tables
- Using SQL comments for tracing served as a “cache buster” — apparently the generic plan cache is keyed on the raw text of the query!
- Postgres exposes a way to configure this behavior; setting plan_cache_mode=force_custom_plan prevents generic plans from being computed and cached entirely
If you needed yet another story for why lines-of-code is not an effective measure of impact, the final resolution of our memory issues was to set this single value on each connection to our primary database (easily done by passing connect_args when creating the engine in SQLAlchemy).
Conclusion
Along with our new knowledge of cache plans in Postgres, our team also emerged with a few learnings that apply to taming the dark art of scaling a production database during periods of rapid iteration; in no particular order:
- incidents can be chaotic, with many moving pieces — maintaining a level head and constantly questioning your assumptions are incredibly valuable skills
- having an airtight release process for quick iteration in prod is critical (thank you to our platform team!)
- Google Cloud SQL reserves 10% of instance memory for other services running on the underlying instance, so database processes are likely to run out of memory when usage exceeds 90%
- If a solution or explanation can’t be deconstructed and reconstructed from multiple perspectives, it’s possible that it isn’t an actual solution
- Observability and tracing are key. Surprisingly, these tools are not always passive participants in your stack!
- plan caches in Postgres are very useful for most standard queries (we definitely saw latency impact on our simple accounts database when toggling this setting), and are destructive for queries over partitioned tables — plan_cache_mode is your friend in this situation
- caching continues to be the root of all evil
Most importantly we want to thank our users and customers for their confidence and trust — which we do not take for granted — as we work harder than ever to strengthen Prefect’s resiliency far ahead of ongoing growth.
The hard-won knowledge represented above was uncovered and compiled by many engineers at Prefect — in particular Zach Angell, Jake Kaplan, Eddie Park, Chris Guidry, Andrew Brookins, and Jonathan Yu spent many restless days and nights experimenting, monitoring and learning to solve the issue described here and significantly improve our overall service reliability and scalability.
To learn more about Prefect:
- visit our website
- join our active Slack community
- ask questions on our Discourse
- follow us on Twitter for updates
- visit us on GitHub to open issues and pull requests
Happy Engineering!
Related Content








