
Keeping Your Eyes On AI Tools
Like everyone else, I've been playing with AI over the last couple of months.
Projects like OpenAI and Hugging Face have made it simpler than ever to interact with LLMs like GPT3—whether it's popping open a new tab in my browser for ChatGPT or making a simple API call with Python.
What is a Large Language Model or LLM?
"Large Language Model" refers to a type of AI model trained on massive amounts of text to generate human-like language. There are open questions about the use of LLMs.
One very interesting way to leverage this new LLM accessibility is being explored by a project called LangChain, the growth of which has exploded.
LangChain is open-source tooling that adds some useful abstractions for interacting with these LLMs, whether that’s:
- callable LLMs to simplify ad-hoc API calls
- successive calls to LLMs + tools to refine answers to questions
- building customized chatbots by persisting information in vector embedding databases, and querying them to provide LLMs with whatever context it needs to answer a question
Through these LLM interactions and others, LangChain is in the business of “enabling developers to build applications that they previously could not.”
I’ll explore some functionality LangChain makes easy, and then present a first pass at a plugin powered by Prefect, which can help us observe our use of LangChain, named langchain-prefect.
Exploring LangChain: Productionizing LLMs
Starting barebones, if I have an OPENAI_API_KEY on my machine, I can go ahead and pip install langchain openai and do a random ol’ LLM call:
1from langchain.llms import OpenAI
2
3llm = OpenAI(temperature=0.9)
4
5answer: str = llm(
6 "What would be a good company name for "
7 "a company that makes colorful socks?"
8)
9
10print(answer) # prints something like `Socktastic!'view rawlangchain-1.py hosted with ❤ by GitHub
This is cool. But, to quote LangChain’s README:
the real power comes when you can combine (LLMs) with other sources of computation or knowledge
A tool like LangChain starts to gets interesting when I integrate other tools, APIs, and embedding databases — but it also starts to get complex enough that orchestration is non-trivial.
Getting pragmatic before building LLM apps
Before I dive headlong into building some LLM-based applications using LangChain, it’s important to think pragmatically about a few things. Let’s say I want to build a chatbot powered by LangChain and some LLM with domain-specific knowledge I can curate and regularly update.
I’d want the chatbot to handle a conversation with a user, answering their questions using the LLM + context + tools at its disposal.
Implementation details aside, I’d need to answer a couple of questions before deploying this chatbot in a production use case.
Ballpark, how much will it cost?
The main currency with these LLMs are tokens — for example, OpenAI charges $0.0200 / 1K tokens to use their DaVinci model. 1 token roughly corresponds to one word, depending on who you ask.
You pay for total tokens, which is prompt tokens + completion tokens, i.e. text you send the LLM + text you get back from it.
If I’m using LangChain agents to make successive LLM calls / leverage tools, and they’re stuffing extra context (tokens) in those calls, how much will that cost me?
Quick experiment and math:
Let’s invoke a LangChain agent like my eventual chatbot might.
It will use the llm-math tool to do the math and fall back to asking the LLM when it doesn’t know the answer (you could add serpapi as a tool here).
1from langchain.agents import initialize_agent, load_tools
2from langchain.llms import OpenAI
3
4llm = OpenAI(temperature=0)
5tools = load_tools(["llm-math"], llm=llm)
6agent = initialize_agent(tools, llm)
7
8answer: str = agent.run(
9 "How old is the current Dalai Lama? "
10 "What is his age divided by 2 (rounded to the nearest integer)?"
11)
12
13print(answer) # The current Dalai Lama's age divided by 2 is 43view rawlangchain-2.py hosted with ❤ by GitHub
When I ran this, the agent made 7 calls to the LLM:
let total, p, c = total_tokens, prompt_tokens, completion_tokens
- total: 205 = p: 172 + c: 33
- total: 254 = p: 242 + c: 12
- total: 243 = p: 224 + c: 19
- total: 244 = p: 239 + c: 5
- total: 282 = p: 256 + c: 26
- total: 245 = p: 242 + c: 3
- total: 316 = p: 293 + c: 23
That shakes out to a grand total of 1789 tokens = $0.03578 = 3.578 cents
Not bad, but this is only one invocation of a barebones agent. If I used other tools (which could be chains/agents) or pulled more context from a vectorstore to stuff in my prompts, that number would rise pretty dramatically — depending on the math you’d have to do for your app.
If you’ve followed along and run the example above, you might wonder how I even figured out my total token usage. It didn’t come back as a return from agent.run 🧐 — but we’ll get to that in just a bit.
So how much does it cost?
It depends. It depends on how well I write my application, what I want it to do, and how well LangChain is leveraging my context when talking to LLMs for me. It certainly seems like something I want to keep track of.
What I haven’t considered here yet at all is infrastructure costs, although, yeah, we will need a scalable and custom runtime for this app.
How do I know that things are working the way I want?
On its face, this seems obvious. It’s working if my users get a useful answer from the chatbot, right?
Well, that’s part of the story for sure. But, this question strikes me as one that’d be most difficult to nail down at production scale — where processes running LLM calls are just one part of a complex workflow.
As abstractions for interfacing with LLMs mature, it feels like it’s going get difficult to keep track of what’s going on under the hood — just like it’s non-trivial to keep track of modern ELT / ETL at production scale.
Hypothetical question: A user opens a support ticket for my chatbot and says my chatbot left them in the cold. How do I know what went wrong?
- Is OpenAI having an incident? did they choke my API calls?
- Is there a problem with my embeddings db?
- Am I orchestrating my LangChain agents/chains incorrectly?
Building tooling to frame and answer these sorts of questions sounds like a lot. But then again, Prefect does kinda do a lot.
Building a Prefect-powered plugin for LangChain
I’ll share some progress on a plugin for LangChain to address some of the pain points I’ve mentioned above, dubbed langchain-prefect.
Let’s first go ahead and pip install langchain-prefect…
and return to that first example, with a new friend named RecordLLMCalls:
1from langchain.llms import OpenAI
2from langchain_prefect.plugins import RecordLLMCalls
3
4llm = OpenAI(temperature=0.9)
5
6with RecordLLMCalls():
7 answer: str = llm(
8 "What would be a good company name for "
9 "a company that makes colorful socks?"
10 )
11
12 print(answer)view rawlangchain-3.py hosted with ❤ by GitHub
117:45:19.782 | INFO | prefect.engine - Created flow run 'scarlet-chital' for flow 'Execute LLM Call'
217:45:21.319 | INFO | Flow run 'Calling langchain.llms.openai' - Sending 'What would be a good company name for a company that makes colorful socks?' to langchain.llms.openai via <function BaseLLM.generate at 0x11e567a30>
317:45:22.211 | INFO | Flow run 'Calling langchain.llms.openai' - Recieved: NotAnArtifact(name='LLM Result', description='The result of the LLM invocation.', content=LLMResult(generations=[[Generation(text='\n\nHappy Feet Socks.', generation_info={'finish_reason': 'stop', 'logprobs': None})]], llm_output={'token_usage': {'completion_tokens': 7, 'total_tokens': 22, 'prompt_tokens': 15}}))
417:45:22.336 | INFO | Flow run 'scarlet-chital' - Finished in state Completed()
5
6Happy Feet Socks.view rawlangchain-4.py hosted with ❤ by GitHub
Uhh, so, what just happened?
Let’s break it down by looking at the logs.
With langchain-prefect you get prefect. With Prefect, you can wrap arbitrary Python functions in a @flow decorator so when you run one of them, metadata on that execution is tracked (see footnotes).
From inside of RecordLLMCalls, the LangChain methods that actually make the API call to the LLM are wrapped in a @flow so that Prefect can track the execution when they are invoked. Prefect gives fun names like scarlet-chital to each flow run, so we see something like:
prefect.engine - Created flow run 'scarlet-chital' for flow 'Execute LLM Call'
Then we see what is actually being sent to the LLM, how the LLM is being prompted by LangChain, the LLM output, and how many tokens we used.
1Flow run 'Calling langchain.llms.openai' - Sending 'What would be a good company name for a company that makes colorful socks?' to langchain.llms.openai via <function BaseLLM.generate at 0x11e567a30>
2Flow run 'Calling langchain.llms.openai' - Recieved: NotAnArtifact(name='LLM Result', description='The result of the LLM invocation.', content=LLMResult(generations=[[Generation(text='\n\nHappy Feet Socks.', generation_info={'finish_reason': 'stop', 'logprobs': None})]], llm_output={'token_usage': {'completion_tokens': 7, 'total_tokens': 22, 'prompt_tokens': 15}}))
3view rawview rawlangchain-5.py hosted with ❤ by GitHub
Finally, since our Python code (or LangChain’s) ran without errors, we see:
Flow run 'scarlet-chital' - Finished in state Completed() Here’s where it gets fun.
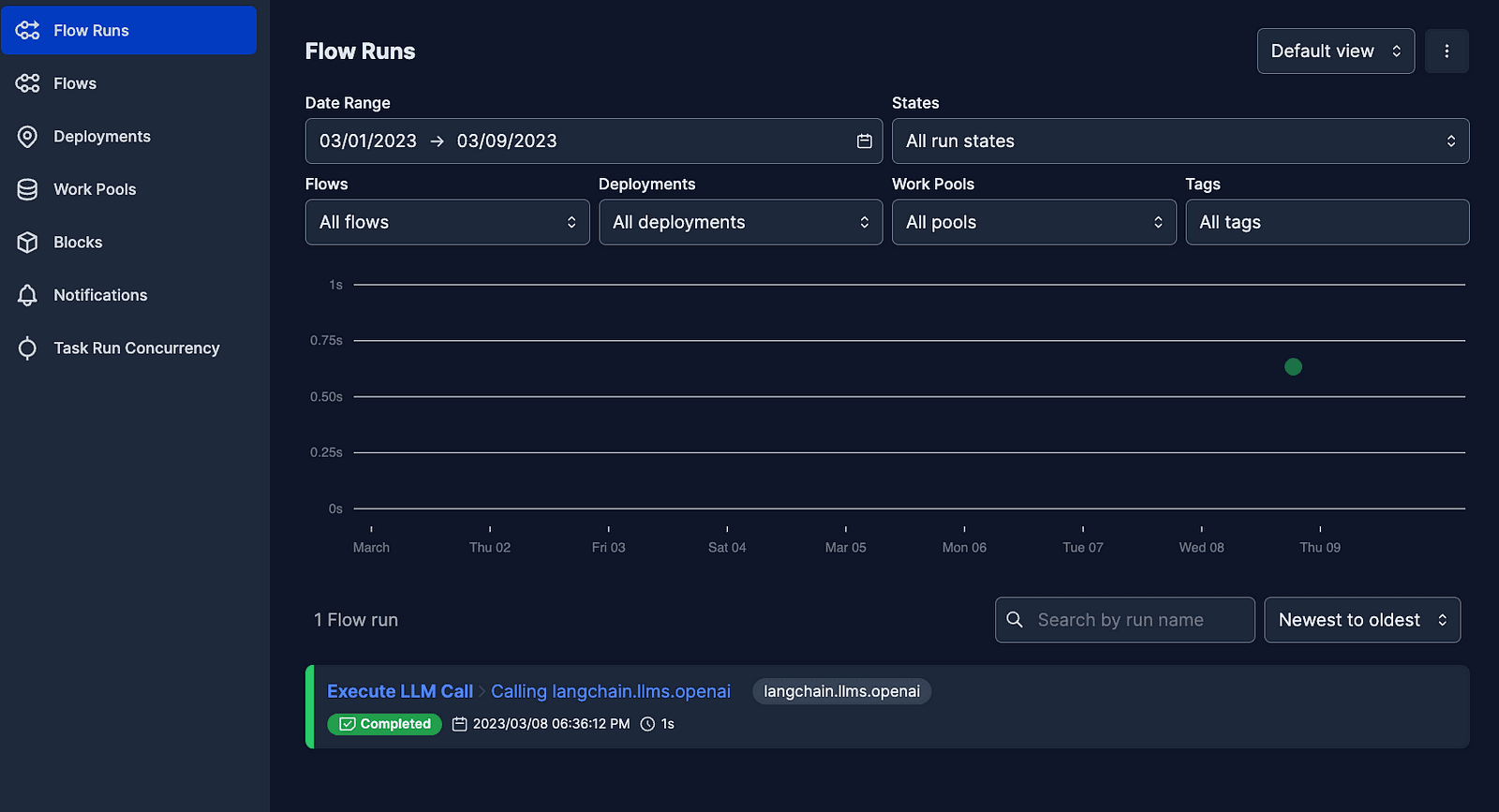
If we pop into a terminal and run prefect server start, you’ll be prompted to Check out the dashboard at http://127.0.0.1:4200…
… where you’ll see a fancy dashboard just waiting to fill up with colors:
The default dashboard view, showing colored dots to represent states of our flow runs
If we click into our flow run, we see:
All the metadata and logs for a given flow run.
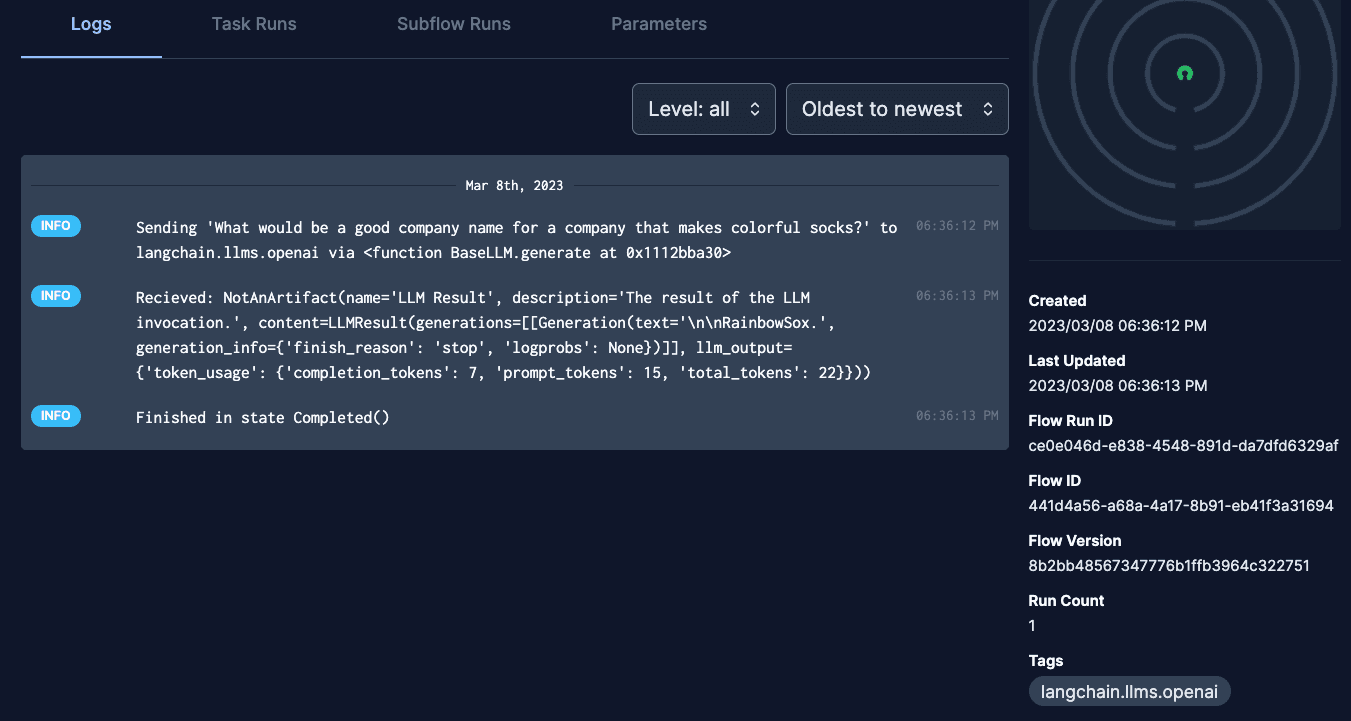
The logs and a bunch of metadata on when, what, and how things happened.
Prefect is uniquely interesting here.
In Prefect, you can call flows from inside other flows — it’s called a subflow. Look what happens if I run the agent example with RecordLLMCalls and add a flow wrapping my agent.run call:
1from langchain.agents import initialize_agent, load_tools
2from langchain.llms import OpenAI
3from langchain_prefect.plugins import RecordLLMCalls
4from prefect import flow
5
6llm = OpenAI(temperature=0)
7tools = load_tools(["llm-math"], llm=llm)
8agent = initialize_agent(tools, llm)
9
10@flow
11def my_flow():
12 """Flow wrapping any LLM calls made by the agent."""
13 return agent.run(
14 "How old is the current Dalai Lama? "
15 "What is his age divided by 2 (rounded to the nearest integer)?"
16 )
17
18with RecordLLMCalls(tags={"agent"}):
19 result = my_flow()view rawlangchain-6.py hosted with ❤ by GitHub
Remember how we ran this earlier, and it made 7 LLM calls? Here they are.
Prefect UI showing the subflow runs (i.e. LLM calls) of `my_flow`
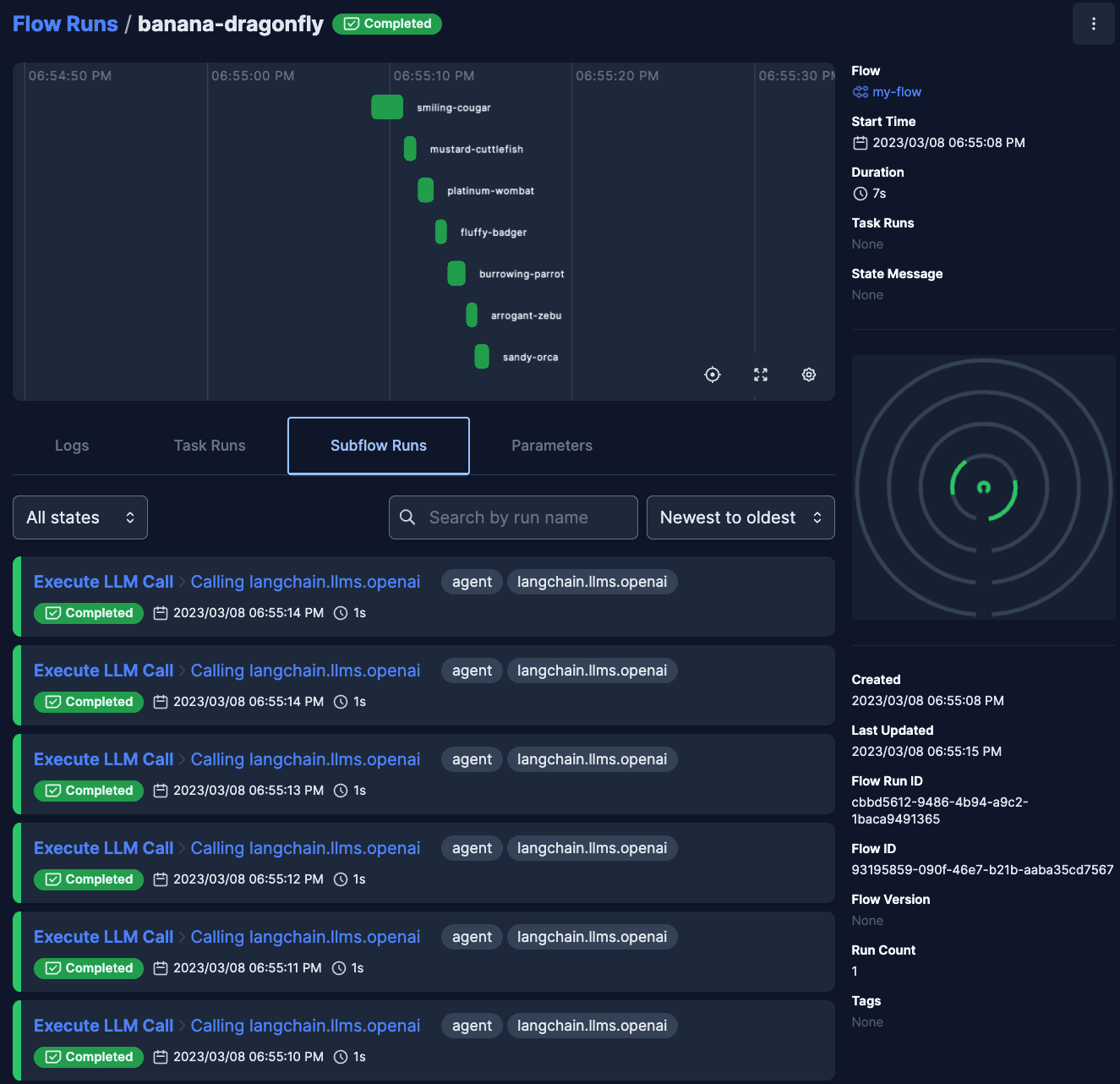
For each one, we’re still tracking LLM input / output and token usage, and now we know where these came from. I used tags={‘agent’} to apply an agent tag to any LLM calls that agent.run created on my behalf.
The nice thing about Prefect flows is that my_flow that wraps these LLM calls could itself be called in the context of a larger workflow (even nested as a subflow of another wrapping parent flow).
Here’s what the usage page looks like in OpenAI:
not the most enlightening
Where do we go from here?
Okay, hopefully that was enough to get the blood flowing. Let’s sum up.
so many possibilities

In general, LLMs are interesting and useful — building apps that use them responsibly feels like a no-brainer. Tools like LangChain make it easier to build LLM apps. We still need to know details about how our apps work, even when we want to use tools with convenient abstractions that can obfuscate those details.
Prefect is built to help data people run, scale, and observe event-driven work wherever they want. It provides a framework for deployments on a whole slew of runtime environments (from Lambda to Kubernetes) on all the main cloud providers. Productionizing LLMs is right up Prefect’s alley.
Among the more advanced concepts in Prefect are results, which are applicable here. Caching common LLM results, aggregating token usage across many actors, and routing good and bad LLM results for use in fine-training all feel like practical choices that results could help implement.
I’m biased, but frankly I’m excited about Prefect’s potential to address the problem of LLM observability. As the AI hype train pushes forward, and we try to balance easy abstractions with control, I believe it will be increasingly important to understand what exactly is happening with applications built on LLMs — the same way it is now for apps built on data warehouses. Real outcomes depend on our tools working as expected.
Stay tuned for further exploration of tools like LangChain! Questions on langchain-prefect or want to contribute? Find and fork the code.
Happy Engineering!
—
Footnotes
How is metadata tracked? By default (with no configuration outside of pip install prefect), Prefect flows spin up a lightweight ephemeral API (FastAPI) and use it to start writing details about flow runs to a SQLite db file ~/.prefect/prefect.db.
You can inspect flow runs with the dashboard after prefect server start.
It’s also super simple to let Prefect Cloud handle UI, API, and DB management for you, for free — but for dev’ing on things, the ephemeral API / local SQLite DB / local UI dashboard is great.
Related Content








