
Event-Driven Versus Scheduled Data Pipelines
Data pipelines shouldn’t follow a rote template. Some can - and, honestly, should - run only periodically, otherwise they become quite costly. Others are so time-sensitive that they need to run immediately in reaction to real-time events.
Consider an accounting process in which underlying data only updates monthly, but you don’t know when. And when it does, you need to process the data within a day. It would be a colossal waste of resources to check for this data daily.
Data pipelines don’t have to always run on a schedule. Many engineering systems already use event streaming tools (Kafka, anyone?) that can be integrated directly with any workflow.
In this article, we look at scheduled vs. event-driven data pipelines, discuss when to use which, and how to create an event-driven data pipeline that’s scalable and observable.
Scheduled vs. event-driven data pipelines
Scheduled data pipelines
A scheduled data pipeline, as its name implies, runs periodically at fixed days and times. This can be once a week, once a day, or even several times a day.
Scheduled data pipelines are routinely used for ingesting data sets of various sizes on a fixed schedule. Scheduled data pipelines are run for data where timeliness is defined in terms of hours or days and upstream data changes are expected and known. A few common examples include:
- Loading data from a transactional database (MySQL/PostgreSQL) to a warehouse (BigQuery/Snowflake)
- Running daily reports to enable business operations across sales/marketing/ecommerce
- Re-training machine learning models based on transformed data
Event-driven data pipelines
Some data use cases need to react to data changes instantly. These are cases where, if you don’t react quickly, your business directly suffers like incurring fraud or a customer missing a delivery.
This is where an event-driven data pipeline comes in.
In an event-driven data pipeline, the pipeline is set up to receive notifications - usually through a webhook. The pipeline receives this type of event from a resource - such as a Kafka topic or a cloud-based queue such as Amazon SQS - whenever an event occurs. The event could come from anywhere - a customer-facing app, a webhook, a data store, etc. The pipeline then processes the event immediately - e.g., updating all necessary data stores with the new data, and issuing alerts and notifications. The end-user - another application, a data analyst - then has the data they need for rapid decision-making.
One example of a use case for an event-driven pipeline is fraud detection. Detecting and denying fraud at transaction time is less costly than unwinding the damage after you’ve discovered it later. Other examples include airline flight cancellations or package delivery updates. All of these have one thing in common: a user, either internal or external, expects an immediate notification upon an upstream change.
Advantages of scheduled vs. event-driven data pipelines
So, that’s all well and dandy. But when should you use one versus the other?
Event-driven pipelines aren’t “better” than scheduled pipelines, and vice versa. Which one you use will depend on a number of factors.
Stakeholder expectations
How often do your stakeholders need a data refresh? For jobs where data freshness expectations can be defined in terms of hours or days, a scheduled pipeline could be a more economical way to process data.
If stakeholders expect to see up-to-the-second data, or need to pull fresh data on demand, you’re better off with an event-driven process. Event-driven pipelines excel in scenarios where the freshness of data is defined in terms of minutes or seconds. Starting a new pipeline run whenever an event occurs obviates the need for constant polling of queues.
Performance considerations
Another issue is how much work a pipeline will process - and what impact that has on running production systems. For example, a data extraction task run against an OLTP data store could consume database connections, memory, etc. that the data store needs to service ongoing customer requests.
With scheduled data pipelines, you can plan to run them when there’s less load on a system. Take the OLTP extraction job. You can schedule this to run outside of peak ordering hours so that the extraction process doesn’t consume database connections and CPU that could otherwise be utilized to process orders.
Infrastructure costs
Every time a pipeline runs, it consumes computing resources. Running infrastructure continuously is also expensive and requires constant monitoring and a team that supports it 24/7. By running a scheduled pipeline only at fixed times, you reduce needless polling of queues and topics and conserve compute costs.
This doesn’t mean “never use event-driven data pipelines,” of course! It means you should consider the economic tradeoffs. It’s absolutely worth investing in the infrastructure required to maintain an eventing system, for example, if doing so prevents millions of dollars in fraud or creates customer loyalty.
Time to maintain
Scheduled data pipelines tend to be easier to observe and monitor. Since they run at set times every day, SREs and data engineers know exactly where to look in their logs and monitoring systems to confirm that the pipeline is working as expected. It’s also easier to re-run failed jobs and get the system back on track than if something goes wrong in an eventing architecture.
Event-driven data pipeline systems will take more time to develop and maintain than a scheduled data pipeline. Again, you should perform a ROI (return on investment) analysis here to verify that the economic value gained from an eventing architecture will offset the investment in infra and ongoing monitoring and maintenance.
Complexity of pipelines
In a complex data ecosystem, event-driven data pipelines can help tame complexity with a loosely-coupled architecture that codifies interactions between teams.
Take our fraud detection example. In this case, the team processing orders can provide transaction data to the fraud detection algorithm through a mechanism such as a topic or a queue. This creates a clear, well-defined point of interaction between the two teams. It also enables the fraud detection team to accept additional data from other teams in a clearly defined way.
Event-driven data pipelines also help reduce complexity when your use case requires quick processing that spans multiple systems. In this case, monitoring and retry logic live independently in each system, which makes it easier to diagnose issues and perform event processing replays in one subset of the architecture.
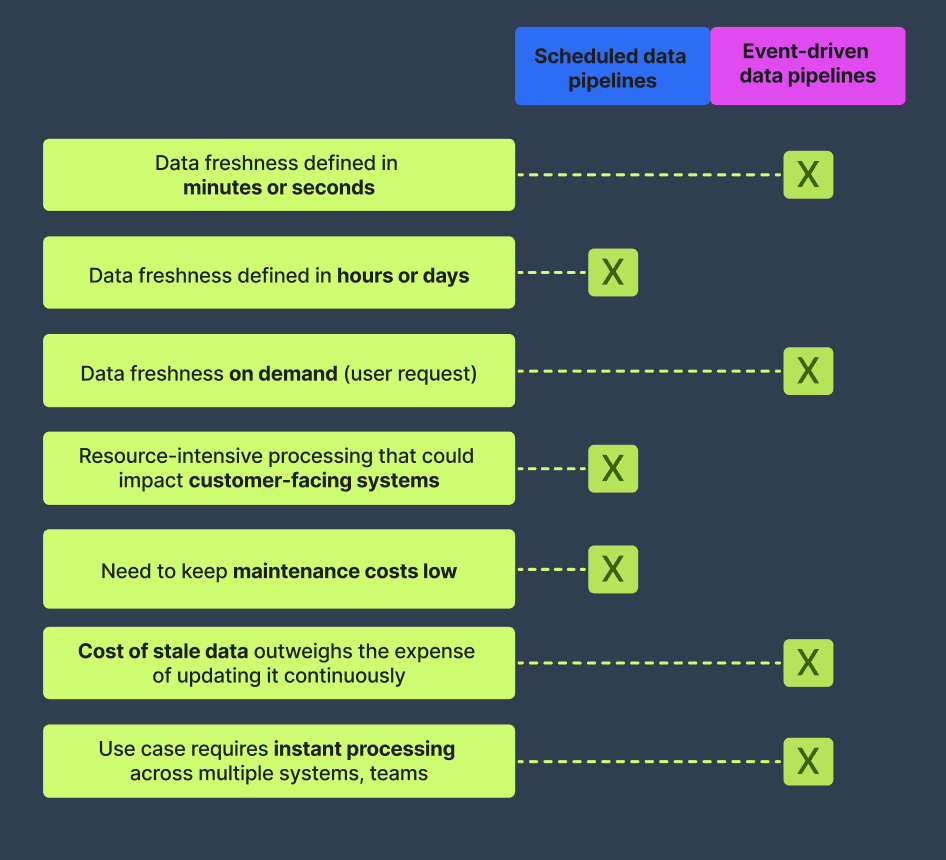
Side-by-side comparison of event-driven and scheduled data pipelines
We can summarize all of the above in the guide below. Use these guidelines to decide when a scheduled data pipeline would work versus when it makes sense to make the extra investment in an event-driven solution.
Implementing an event-driven data pipeline
The most straightforward way to implement an event-driven approach is by using webhooks. In this pattern, you register a remotely hosted REST API function with the target eventing system. The eventing system then calls your API endpoint whenever it receives a new message that requires processing. Simple and done.
Serverless functions on cloud providers like AWS offer a variation on this webhook pattern. In AWS, for example, you can use features such as Amazon SQS or Amazon EventBridge to run AWS Lambda functions in response to queue messages or CloudWatch events. However, as we’ve discussed before, serverless functions can be hard to monitor at scale.
You can also implement event-driven data pipelines through polling - i.e., running code that periodically checks (every few seconds, minutes, hours, etc.) an external resource such as a topic of queue. In this case, the pipeline is more of a “scheduled-event” design pattern.
Event-driven data pipelines with Prefect
Over time, scheduled and event-driven data pipelines can become a significant and vital part of your overall application architecture. However, monitoring them across your entire infrastructure can be painful, especially as your systems grow.
You may also run into issues scaling your pipelines. Traditional tools such as Airflow hit hard limits as your pipelines grow in complexity and start to resemble full-blown data engineering stacks in their own right. This lack of scaling can lead to processing delays that undermine the need for fast, near-real-time processing in event-driven data architectures.
Prefect is a workflow observability platform that supports scheduled and event-driven data pipelines at any scale. Prefect’s webhooks support means that event-driven workflows are a first-class concept. Prefect can efficiently scale your infrastructure where it actually runs by taking advantage of serverless and auto-scaling cloud infrastructure.
Getting started with event-driven data pipelines on Prefect
You can implement an event-driven data pipeline on Prefect in just a few steps. First, you create a webhook. The screenshot below shows how you’d define a webhook in Prefect. Once defined, Prefect will supply a URL you can register in your external system - e.g., as an Httpsink in Confluent:
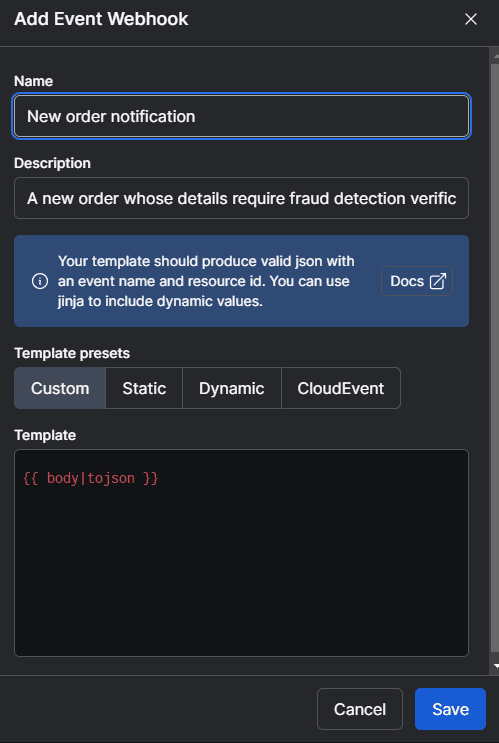
Prefect supports Jinja templates so that you can transform the JSON payload from Amazon SNS into any format you need. In this case, we use a pass-through command to send our job the raw JSON data.
You would then create an SNS topic and subscribe your HTTPS endpoint to it. You can then send messages to your SNS queue, which will be sent directly to the Prefect webhook:
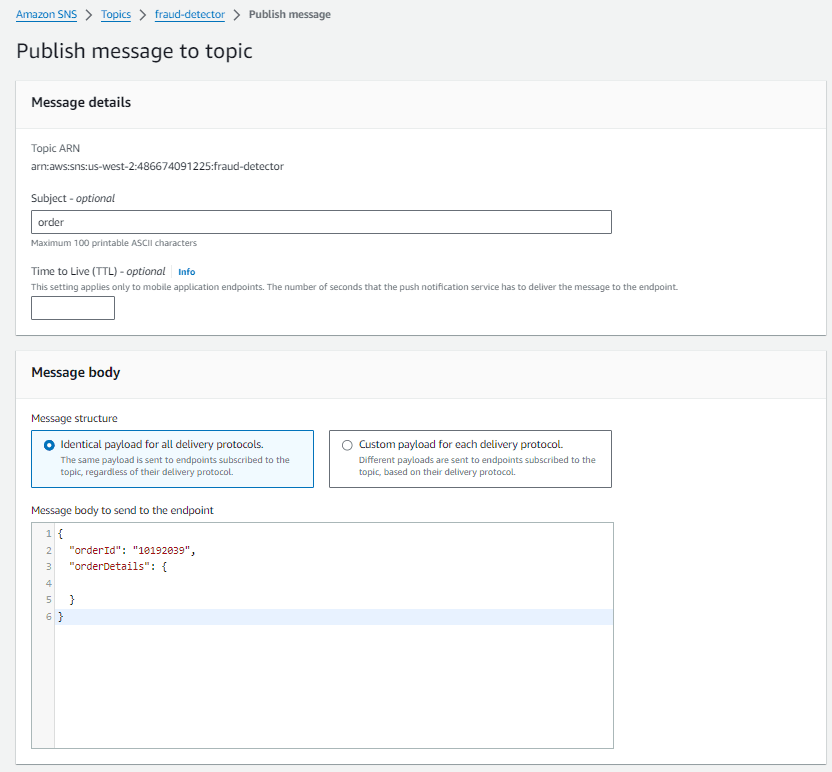
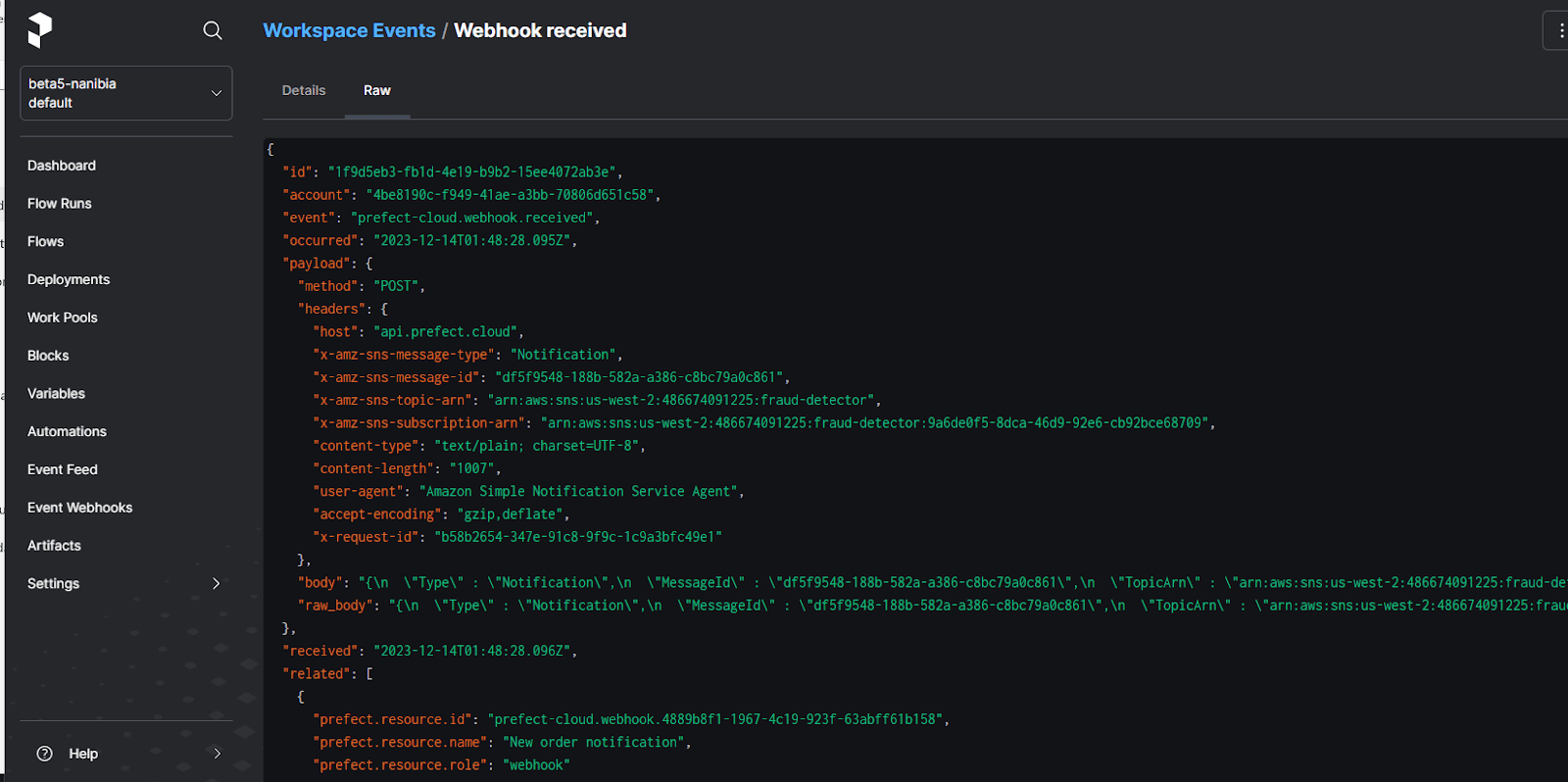
Next, you would define a Prefect flow that implements the processing logic. (In a real-world example, this is also where you would implement automatic subscription confirmation logic for the SNS topic.) After performing its work and making a decision, the workflow would send a notification back to the application via a mechanism such as a queue message, SNS notification, or direct API call.
1@flow
2def process_request():
3 do_work()
4
5if __name__ == "__main__":
6 process_request.serve(name="process-request-deployment")After deploying our flow, we can select a sample event from our Event Feed and use the Automate command to create a trigger and select the deployment to invoke.
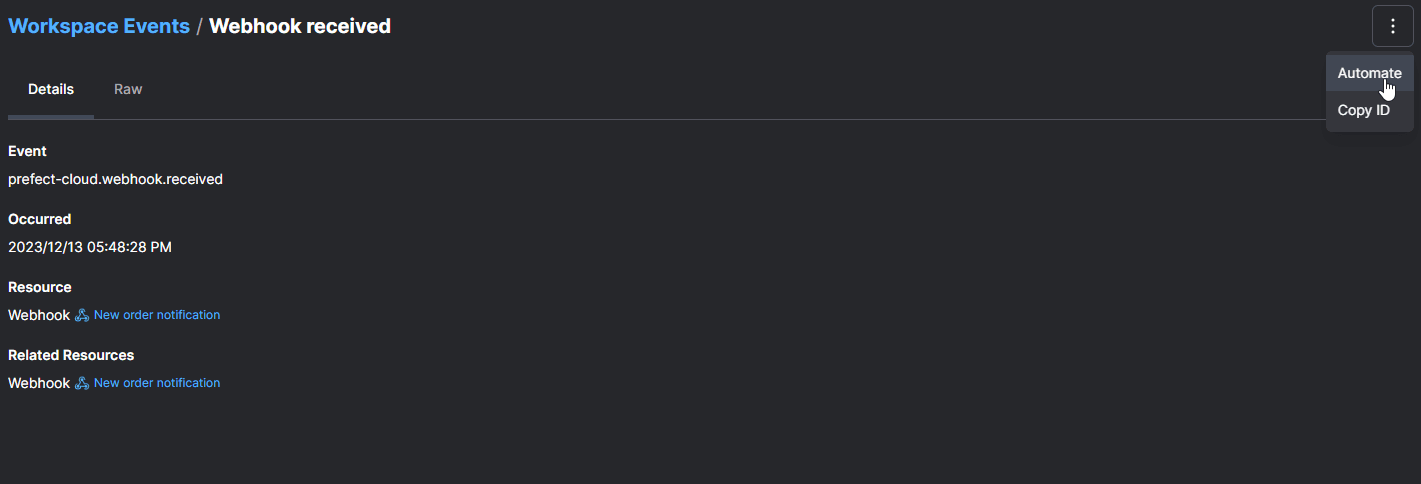
For a full example of creating an event-driven pipeline using Kafka topics and the Confluent Httpsink connector, see Event-Driven Flows with Prefect.
Final thoughts
Both scheduled and event-driven data pipelines play important roles in a scalable data-driven ecosystem. Using Prefect, you can create, manage, and scale both types of pipelines across your entire infrastructure from a single, centralized location.
To try it out yourself, sign up for a free Prefect account and create your first workflow.
Related Content








