Schedule Python Scripts
One of the most frustrating parts of the workday is doing something that could be automated, but just… isn’t yet.
This busywork is incredibly disruptive. And the worst part is: if you don’t proactively root out these monotonous automatable tasks, they won’t go away on their own. Instead, they’ll grow, and before you know it they will have consumed a huge part of your week.
My team was plagued by one of these time-sucking, manually-executed yet highly-automatable tasks. Every week on Monday morning, one of my team's very talented engineers would come into the office, sit down at her desk, and run a Python script. Every single week.
Sounds like a job for scheduling, right? Although your reflex might be to reach for cron, running the script was really only the first of five problems that had collectively consumed nearly half of my teammate’s work-week.
In this post, you’ll hear about the five problems my team faced, spanning scheduling, error handling, observability, concurrency and scaling, and data persistence. By the end, you’ll learn how Prefect helped us solve all of them.
The Dreaded Python Script
Let’s shine some light on my team’s incredibly frustrating time vampire 🧛🏻♂️. One of my team’s goals was to determine the best time series forecasting model for a handful of use cases.
Here’s our starting point:
def run_pipeline() -> float:
# TODO: This fails sometimes. Just run it again if it does.
data = get_data()
# Backtest models on recent data
predictions = {model_name: backtest(model_name, data) for model_name in MODELS.keys()}
# Compute metrics using backtested predictions
metrics = {model_name: run_metric(data, pred) for model_name, pred in predictions.items()}
# Write metrics report to file
# TODO: Again, don't overwrite old files!
pd.DataFrame.from_dict(metrics, orient="index").to_markdown("out/metrics.md")
# Choose the best performing model and predict next week's value.
best_model = choose_best_model(metrics)
next_week = run_model(best_model, data)
# Write next week's prediction to file
# TODO: Seriously, stop overwriting the files!
pd.DataFrame({best_model: [next_week]}).to_markdown("out/next_week.md")
return next_weekOur script downloaded data, backtested our models, computed metrics, selected the best performing model, and finally used that model to make next week’s prediction– all while (poorly) saving some results to file along the way.
To address our problems, my team used the Prefect library to make our script a workflow. This allowed us to schedule and observe it, while including our users by giving us the option to send them the script’s outputs regularly.
Schedule Python with Python
Problem #1: Running a script at a particular time is a problem for computers, not humans. 🤖
We can schedule our Python script to run every week with just a few lines of code and a simple cron string. But before that, we needed to turn our run_pipeline function into a Prefect flow. This is really simple… just import the @flow decorator and apply it to our function.
from prefect import flow
@flow
def run_pipeline() -> float:
...We could then use our flow’s serve() method to easily schedule our script to run at midnight every Monday morning. This way, our script’s results were ready to review in time for our morning coffee ☕.
if __name__ == "__main__":
run_pipeline.serve(name="weekly-prediction", cron="0 0 * * MON")
Problem solved! 🎉 Or, it would be if our original script wasn’t a heaping pile of technical debt held together with hopes and dreams 🌈.
Handling Python Code Failures
Problem #2: Scheduled Python code can fail, and needs to be rerun before the next schedule. Then what?
Our get_data method relies on an unreliable endpoint. When it fails, our whole script will crash, and our only recourse is to cross our fingers and try again 🤞.
# TODO: This fails sometimes. Just run it again if it does.
data = get_data()Fixing this upstream data source was outside of my team’s control, so we needed to make our flow more resilient to failures. How do we do that? To start, we can turn our helper functions into tasks using the @task decorator.
@task
def get_data():
return our_team.get_data()
@task
def backtest(model_name, data):
model = MODELS[model_name]
preds = our_team.backtest(model, data)
# Write predictions to file
# TODO: Don't overwrite old files.
pd.DataFrame(preds).to_markdown(f"out/{model_name}.md")
return preds
@task
def run_metric(truth: pd.DataFrame, pred: pd.DataFrame) -> pd.DataFrame:
return our_team.metric(truth, pred)
@task
def choose_best_model(metrics):
best_model_name, _ = min(metrics.items(), key=lambda x: x[1])
return best_model_name
@task
def run_model(model_name, data):
return MODELS[model_name].fit(data).predict()Like flows, tasks give us a bunch of powerful functionality including capabilities specifically designed for improving scaling and error handling. For our get_data task, we can use the retries argument to specify the number of times to try a task before giving up.
@task(retries=42)
def get_data():
return our_team.get_data()Now, Prefect will retry up to 42 times until it succeeds. Because it never fails that much, this solves our flaky data problem. ✅ So, I was a bit premature in the last section, but is our “problem solved 🎉” now?
Although we’ve scheduled our script (and can guarantee it will run successfully), I wasn’t ready to consider the mission accomplished yet. Most frustratingly, our process would still rely on one person to update the team on the script’s status.
However, by structuring our script as a collection of @flows and @tasks, we had already done all the legwork to leverage the rest of Prefect’s ecosystem. So, let’s keep going to see what useful capabilities we’ve unwittingly unlocked.
Team-Wide Workflow Observability
Problem #3: Only one person on our team knows the status of our pipeline, and what they do know isn’t enough.
My favorite feature of Prefect is its web-based UI. You don’t even need to write any more code to use it!
To spin up a local Prefect server run prefect server start. Or we can use the free tier of Prefect Cloud for even more cool features. Check out this page for a quick walkthrough on how you could get signed up and running in just a few minutes.
Spinning up Prefect’s UI is probably the fastest way to blow your team’s mind after upgrading your workflows from simple Python scripts 🤯. In our case, what was once tqdm progress bars and log files accessible only from a specific workstation had become an interactive dashboard available from any of my team’s browsers.
Some of the main insights we most appreciated were:
- a history of all upcoming and past flow runs
- flow- and task-level logs
- timing results
- status indicators (completed, failed, pending, etc.)
- and a real time graphical view of our flow and all of its tasks.
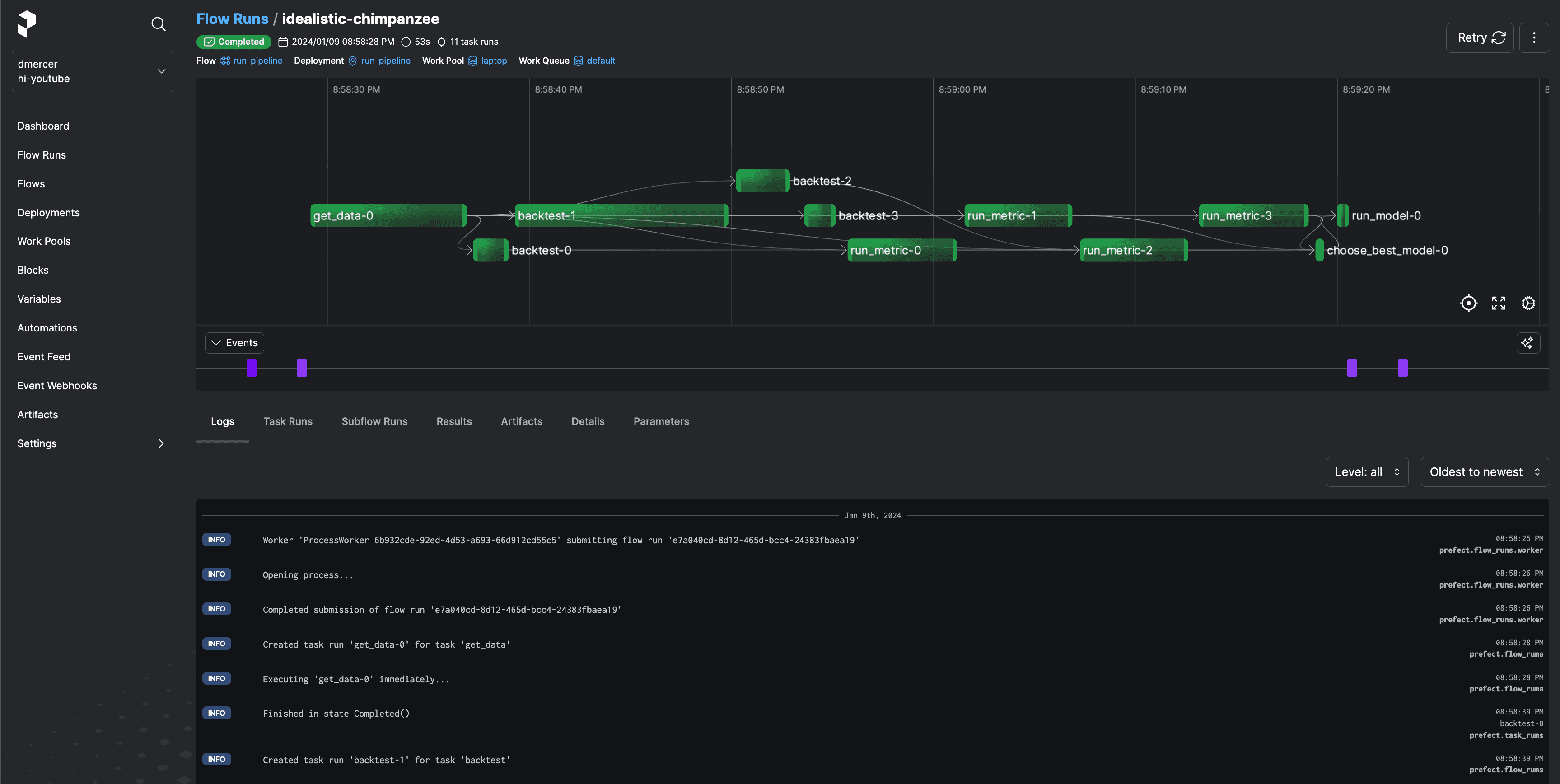
As we dug into our flow using Prefect’s UI, we realized something.

We spend the majority of our time processing our backtests and metrics one by one. Let’s fix that.
Concurrency and Scaling Infrastructure for Scheduled Python Workflows
Problem #4: Our code is embarrassingly slow even though it’s embarrassingly parallelizable.
With each new model, our pipeline’s running time became a bit more out of hand. What was once hours had become days, and before long we worried that our “weekly” pipeline would bust at the seams and expand into the following week.
But… why? Each model is independent, and in isolation each took at most a few hours to run. We had a scaling problem. Until now, we hadn’t made the effort to properly scale our work, but now that we’d converted our pipeline into tasks and flows it was really easy to make the jump to a truly scalable workflow. Our initial goal was to schedule Python, but this type of work quickly requires more scaling considerations.
Concurrency
First thing’s first: we need to make our independent tasks run concurrently. We can do this by leveraging Prefect’s asynchronous programming capabilities.
A task’s map method lets us easily submit a task run for each item in an iterable. In our case, we can use it to create a task run for each of our models. However, the backtest task requires our data DataFrame. Since data is iterable, if we aren’t careful we’d create a task run for each element in our dataset. To avoid that, we can use the unmapped annotation.
from prefect import unmapped
prediction_futures = backtest.map(MODELS.keys(), unmapped(data))This gives us a list of PrefectFutures– one for each of our models. Since we want a dictionary of prediction dataframes, we’ll use a dictionary comprehension and call each PrefectFuture’s result method:
predictions = {model_name: pred.result() for model_name, pred in zip(MODELS.keys(), prediction_futures)}We can do the same for our metrics, again using unmapped to ensure that we pass the entire dataset to each task run.
metric_futures = run_metric.map(unmapped(data), predictions.values())
metrics = {model_name: metric.result() for model_name, metric in zip(predictions.keys(), metric_futures)}These two changes allow us to turn what was once a needlessly sequential computation into a concurrent one.

Scaling
By default, Prefect uses an asynchronous concurrent task runner to allocate task runs to executors. This runner works well if you have a lot of IO or network operations, but our use case involves a lot of compute-heavy tasks.
Prefect has several options for achieving true parallelism and scaling your compute capabilities beyond a single system. My team reached for the prefect-dask integration library to distribute our work across a Dask cluster. Simply install prefect-dask by running pip install prefect-dask, import the DaskTaskRunner, and tell our flow to use it.
from prefect_dask import DaskTaskRunner
@task(task_runner=DaskTaskRunner())
def run_pipeline() -> float:
...Beyond Dask, Prefect also supports a RayTaskRunner available in the prefect-ray library which can be used in a similar manner as the DaskTaskRunner.
Alternatively, you can configure Prefect to execute tasks using all the major cloud platforms via other integrations, and even monitor functions in those other platforms simply with decorators and events.
Persist and Share Workflow Output
Problem #5: Would you PLEASE stop overwriting files! 🙃
Our code is really shaping up, but there are still a lot of TODOs…
@task
def backtest(model_name, data):
model = MODELS[model_name]
preds = our_team.backtest(model, data)
# Write predictions to file
# TODO: Don't overwrite old files.
pd.DataFrame(preds).to_markdown(f"out/{model_name}.md")
return preds
@flow(task_runner=DaskTaskRunner())
def run_pipeline() -> float:
...
# Write metrics report to file
# TODO: Again, don't overwrite old files!
pd.DataFrame.from_dict(metrics, orient="index").to_markdown("out/metrics.md")
...
# Write next week's prediction to file
# TODO: Seriously, stop overwriting the files!
pd.DataFrame({best_model_name: [next_week]}).to_markdown("out/next_week.md")
return next_weekEvery time we run our flow, we’re overwriting last week’s results. That’s not good, but there’s an easy fix. We can use Prefect’s artifact system to create artifacts. Artifacts in Prefect are just stored pieces of data that are generated within flow or task runs. Rather than writing our predictions as a Markdown file to disk, we can create a Markdown report using the create_markdown_artifact function.
from prefect.artifacts import create_markdown_artifact
@task(task_run_name="backtest-{model_name}")
def backtest(model_name: str, data: pd.DataFrame) -> pd.DataFrame:
model = MODELS[model_name]
preds = our_team.backtest(model, data)
create_markdown_artifact(
key=f"{model_name}-predictions",
markdown=preds.to_markdown(),
)
return predsOr, we can use the create_table_artifact function to make a table artifact from a Python dictionary.
from prefect.artifacts import create_table_artifact
# Compute metrics using backtested predictions
metric_futures = run_metric.map(unmapped(data), predictions.values())
metrics = {
model_name: metric.result()
for model_name, metric in zip(predictions.keys(), metric_futures)
}
# Make an artifact for the metrics table
create_table_artifact(key="metrics", table=[metrics])
We can find our artifacts within the flow run or task run pages within Prefect’s UI. Artifacts accessible from Prefect UI’s Flow Page, showing the flow and task run artifacts. Or better yet, since we named our artifacts, we can find them on the Artifacts tab.

An example of the “next-week” prediction artifact, showing the prediction and model name used for a particular flow run. We can easily look back through our predictions artifact to determine which model we used and what it predicted. Prefect UI’s Artifacts Page, showing all the history of all next-week artifacts.
Five Problems of Scaling Our Scheduled Python Work - Solved
Let’s recap the five problems that Prefect helped us solve.
- We saved someone’s Monday morning by scheduling our Python script with Prefect.
- We added retries and error handling to gracefully resolve and recover from unforeseen failures.
- We got a super useful web-based UI that gives us all the information that we could possibly need to debug and monitor our data pipelines and react to unexpected situations.
- We massively sped up our pipeline by running a bunch of our tasks concurrently, and scaled our computation beyond a single machine by using one of Prefect’s many integrations with external infrastructure or on-prem compute clusters.
- We got an easy way to maintain a history of all the data and reports that our workflow generated through Prefect’s artifact system.
The act of scheduling Python workflows is usually just the beginning, because problems and scaling and reliability typically follow shortly after. When scheduling your workflows, consider these potential difficulties from the start to save your future self a lot of time and frustration down the line.
What’s next?
Prefect lets you build, observe, and react to all sorts of data pipelines. This post just scratched the surface of all the awesome things that Prefect can do. Prefect’s cloud product levels up your workflow orchestration with true end-to-end observability, so you never have to wonder what’s happening with your workflows.
If you want to learn more about this use case, you should check out this video that dives into more detail than I could cram into this blog post.
Try Prefect Cloud for free for yourself, download the open source package, join Prefect’s Slack community, or talk to one of Prefect’s engineers to learn more.