


Build and monitor bulletproof data pipelines
Turn your failing scheduled jobs into resilient, recurring workflows without torturing your code.

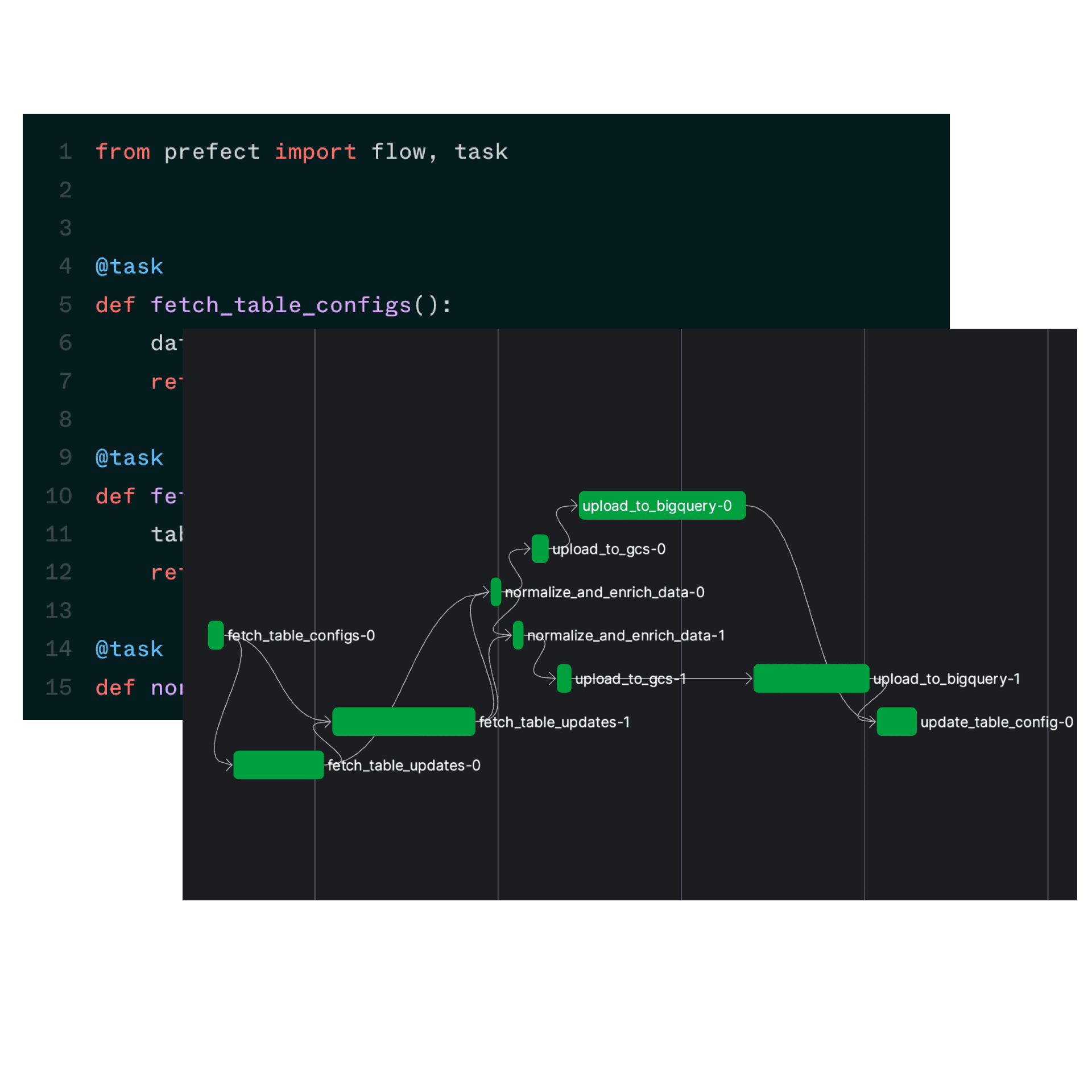







Build data pipelines faster
Stop writing boilerplate and ship your workflows to production at speed.
- Pythonic syntax
- Flexible infrastructure model
- Customizable IFTTT-style automations
- Native events and webhooks

Recover from failure, quickly
Build self-healing workflows with automations and retries, or return to normal with insights into failure and granular inspection of individual flows.

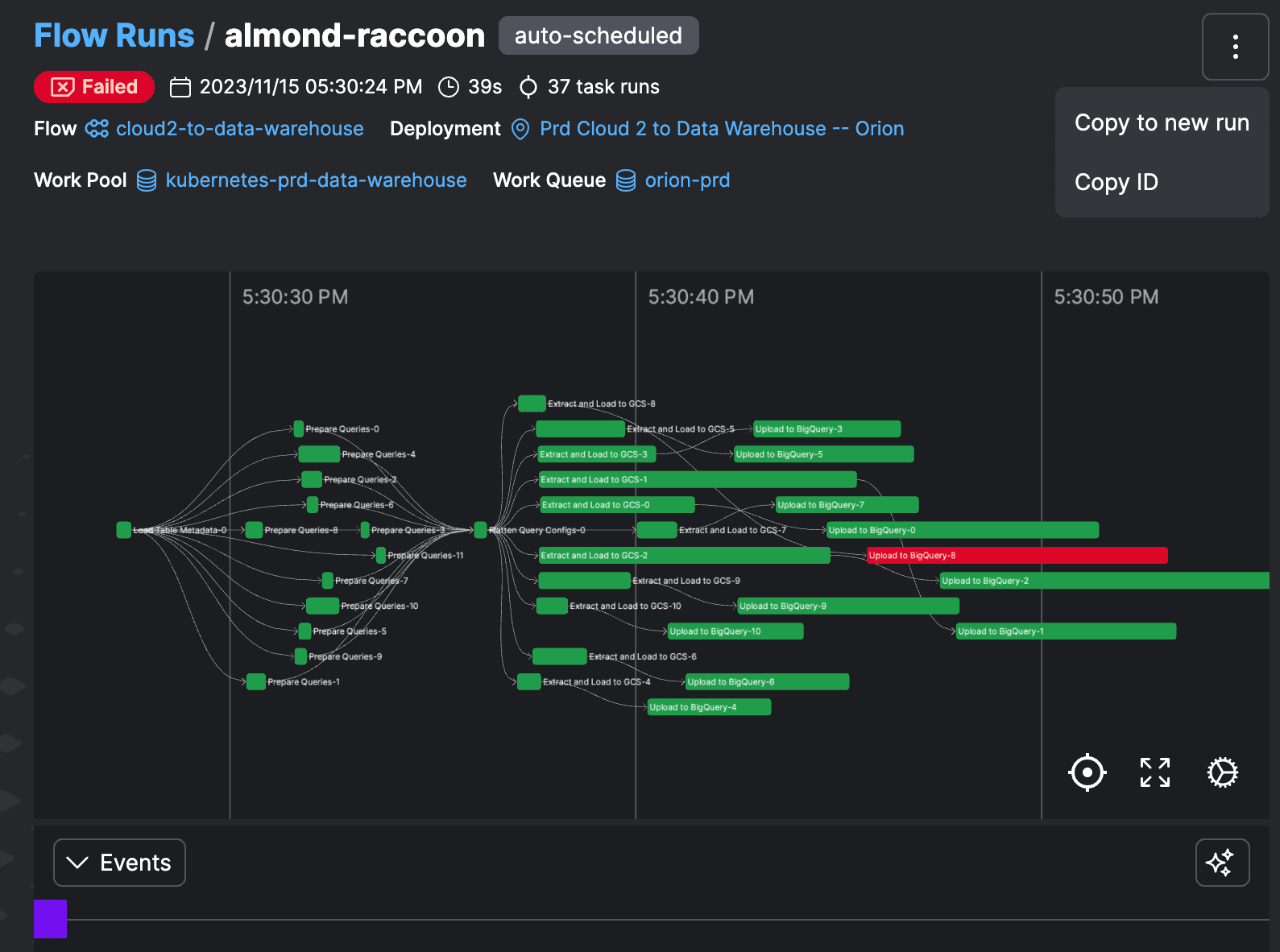
From dev to prod without a hitch
Prefect's architecture means you can promote to production without worry - your code runs as expected on the infrastructure you choose, without changes.

Learn About Prefect
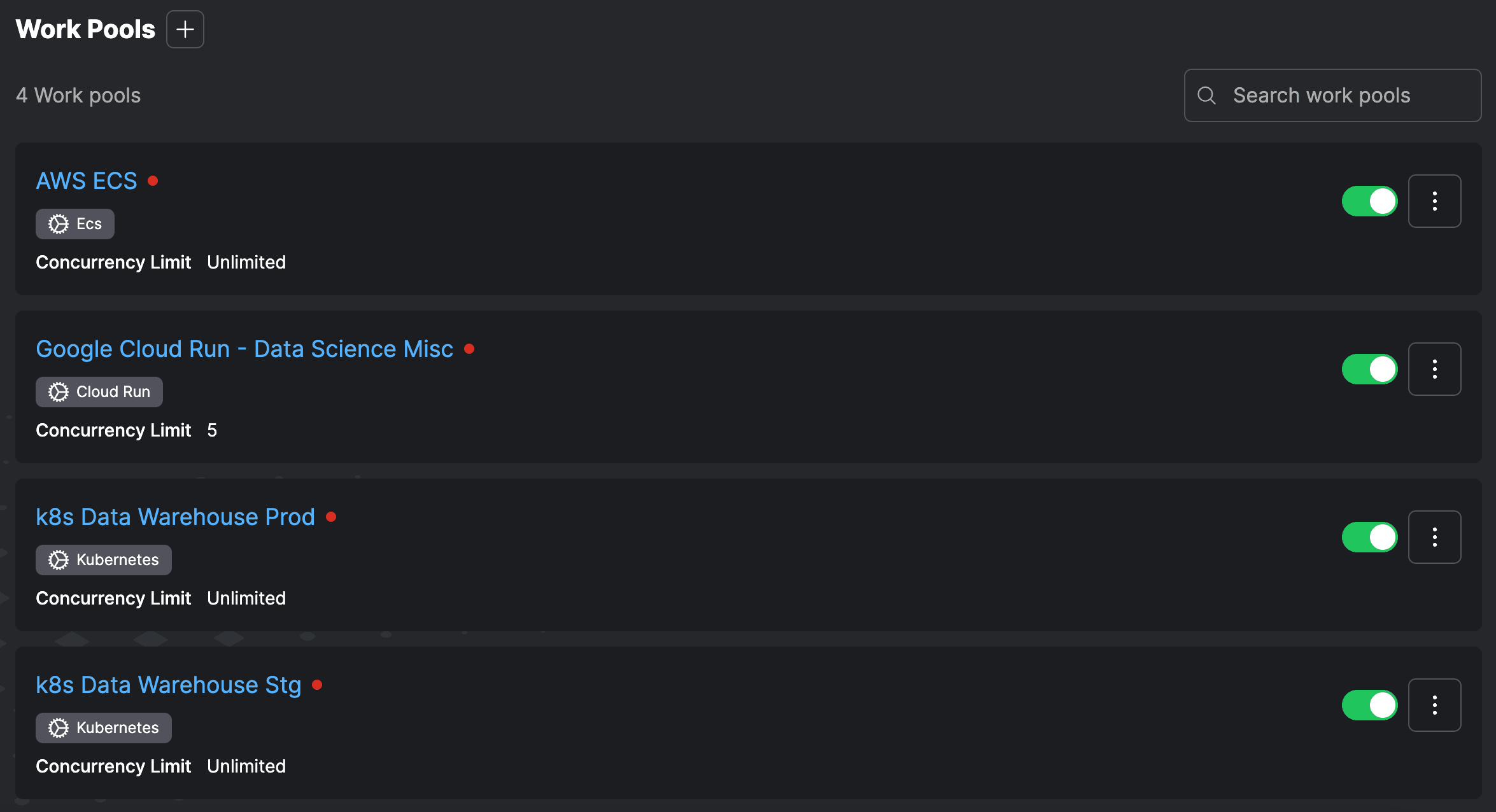
A versatile, dynamic framework
From batch ETL scheduling to complex operational workflows: if python can write it, Prefect can orchestrate it.
- Events & webhooks
- Automations
- DAG discovery at runtime

1from prefect import flow, task
2
3@task
4def add_one(x: int):
5 return x + 1
6
7@flow
8def main():
9 for x in [1, 2, 3]:
10 first = add_one(x)
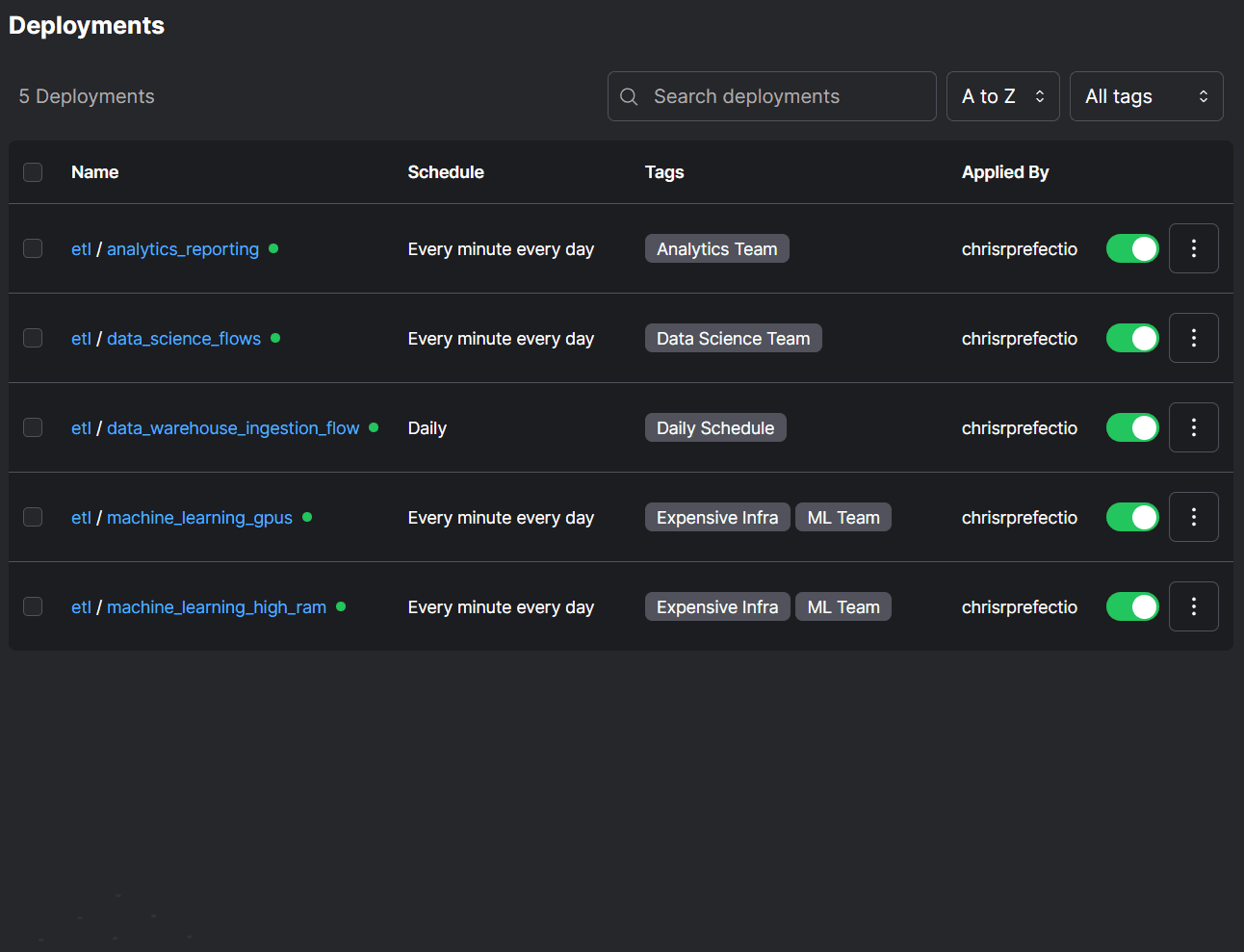
11 second = add_one(first)Consolidate your scheduling
Stop stitching together fragile workflows that break across multiple tools.
Unify your scheduling and get a complete picture of your system health and granular insights into what broke, when.

Don't change how you write code
1import yfinance as yf
2
3
4def extract(ticker):
5 data = yf.download(tickers=ticker, period='10d', interval='1h')
6 return data['Close'] # Extract only the 'Close' data
7
8def transform(data):
9 sma = data.rolling(48).mean()
10 return sma
11
12def load(sma):
13 print(sma)
14
15def etl(ticker='SNOW'):
16 extracted_data = extract(ticker)
17 transformed_data = transform(extracted_data)
18 load(transformed_data)
19
20
21if __name__ == "__main__":
22 etl()
23
24
25
26
27 1import yfinance as yf
2from prefect import flow, task
3
4
5@task
6def extract(ticker):
7 data = yf.download(tickers=ticker, period='10d', interval='1h')
8 return data['Close'] # Extract only the 'Close' data
9
10@task
11def transform(data):
12 sma = data.rolling(48).mean()
13 return sma
14
15@task
16def load(sma):
17 print(sma)
18
19@flow
20def etl(ticker='SNOW'):
21 extracted_data = extract(ticker)
22 transformed_data = transform(extracted_data)
23 load(transformed_data)
24
25
26if __name__ == "__main__":
27 etl.serve(name="moving_average_deployment",cron="* * * * *")